
背景
有时,我们需要删除Java源代码中的注释。目前有不少方法,比如:
实现状态机。该方式较为通用,适用于多种语言(取决于状态机支持的注释符号)。
正则匹配。该方式容易误判,尤其是容易误删字符串。
利用第三方库。该方式局限性较强,比如不同语言可能有不同的第三方库。
本文针对Java语言,介绍一种利用第三方库的方式,可以方便快速地移除代码中的注释。
原理
这个第三方库叫做JavaParser。它可以分析Java源码,并生成语法分析树(AST),其中注释也属于AST中的节点。
因此核心思路即为:
JavaParser解析源码并得到AST。
识别出注释类型的节点并将其删掉。
将AST中剩余的节点按一定规则打印出来。
在实践之前,我们先要了解Java中的几种注释类型:
LineComment 单行注释。
BlockComent 块注释。
JavadocComment Java文档注释。
下面举个简单例子,说明三种注释的区别:
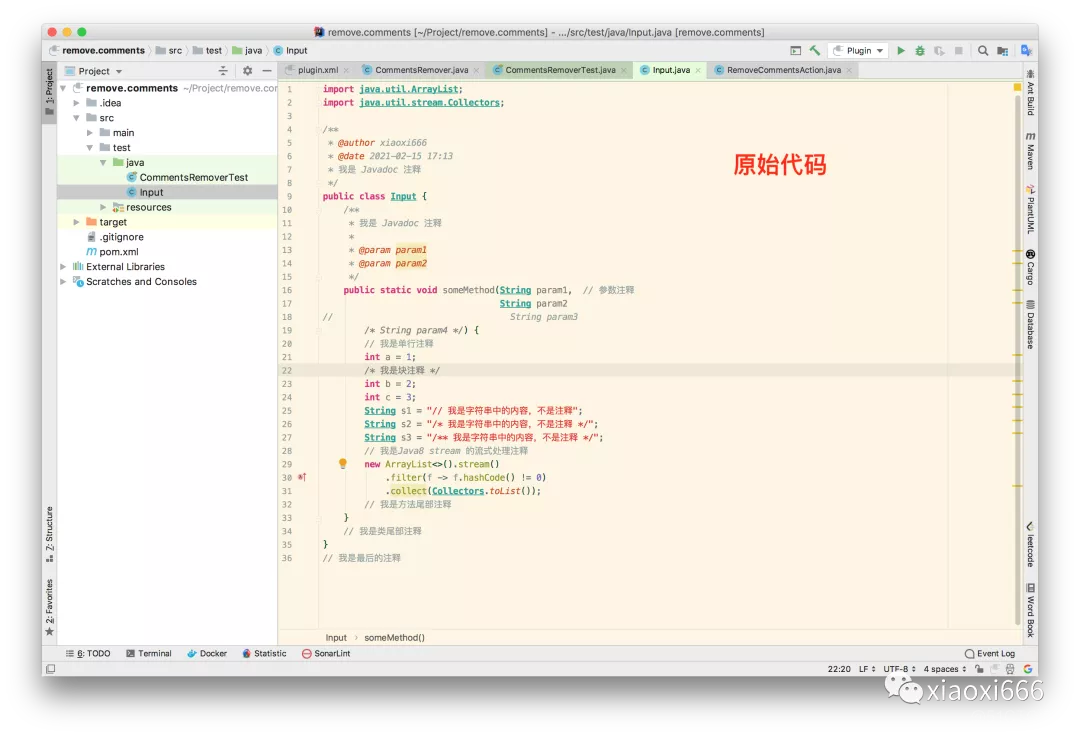
import java.util.ArrayList;import java.util.stream.Collectors;/*** @author xiaoxi666* @date 2021-02-15 17:13* 我是 Javadoc 注释*/public class Input {/*** 我是 Javadoc 注释** @param param1* @param param2*/public static void someMethod(String param1,String param2){// 我是单行注释int a = 1;/* 我是块注释,注意我和Javadoc注释的区别,我只有一个星号 */int b = 2;/** 我是块注释*/int c = 3;String s1 = "// 我是字符串中的内容,不是注释";String s2 = "/* 我是字符串中的内容,不是注释 */";String s3 = "/** 我是字符串中的内容,不是注释 */";}}
下面我们实践一下,看看怎么移除源码中的注释。
我这里使用maven管理项目,首先引入JavaParser依赖:
<dependencies><dependency><groupId>com.github.javaparser</groupId><artifactId>javaparser-symbol-solver-core</artifactId><version>3.18.0</version></dependency></dependencies>
然后编写核心代码:
package core;import com.github.javaparser.JavaParser;import com.github.javaparser.ParseResult;import com.github.javaparser.ParserConfiguration;import com.github.javaparser.ast.CompilationUnit;import com.github.javaparser.ast.Node;import com.github.javaparser.ast.comments.BlockComment;import com.github.javaparser.ast.comments.Comment;import com.github.javaparser.ast.comments.LineComment;import com.github.javaparser.printer.lexicalpreservation.LexicalPreservingPrinter;import java.util.List;import java.util.Optional;import java.util.stream.Collectors;/*** @author xiaoxi666* @date 2021-02-15 20:09* 几个注释的概念:* LineComment* BlockComment* JavadocComment */public final class CommentsRemover {private CommentsRemover() {}public static String doAction(String content) {JavaParser javaParser = createJavaParser();ParseResult<CompilationUnit> result = javaParser.parse(content);Optional<CompilationUnit> optionalCompilationUnit = result.getResult();if (!optionalCompilationUnit.isPresent()) {return "";}CompilationUnit compilationUnit = optionalCompilationUnit.get();removeComments(compilationUnit);return LexicalPreservingPrinter.print(compilationUnit);}private static void removeComments(CompilationUnit compilationUnit) {List<Comment> comments = compilationUnit.getAllContainedComments();List<Comment> unwantedComments = comments.stream().filter(CommentsRemover::isValidCommentType).collect(Collectors.toList());unwantedComments.forEach(Node::remove);}/*** 创建源码解析器。我们设置LexicalPreservationEnabled为true,保留源码中的所有语法。** @return JavaParser*/private static JavaParser createJavaParser() {ParserConfiguration parserConfiguration = new ParserConfiguration();parserConfiguration.setLexicalPreservationEnabled(true);return new JavaParser(parserConfiguration);}/*** 我们只识别单行注释和块注释** @param comment* @return true if meet the correct type*/private static boolean isValidCommentType(Comment comment) {return comment instanceof LineComment || comment instanceof BlockComment;}}
在上面的代码中,我们首先创建JavaParser,再解析源码,然后移除单行注释和块注释,最后再用LexicalPreservingPrinter将处理后的源码打印出来,这个打印器可以保留源代码所有词法,比如空格、换行之类的元素。上述代码已有注释,因此不再详述。
封装为IDEA插件
考虑到我们平时可能会大量使用该功能,因此将其封装为了IDEA插件,名为remove.comments。下面简要介绍该插件的工作原理及使用方式。PS:本文不会详细介绍如何编写IDEA插件。
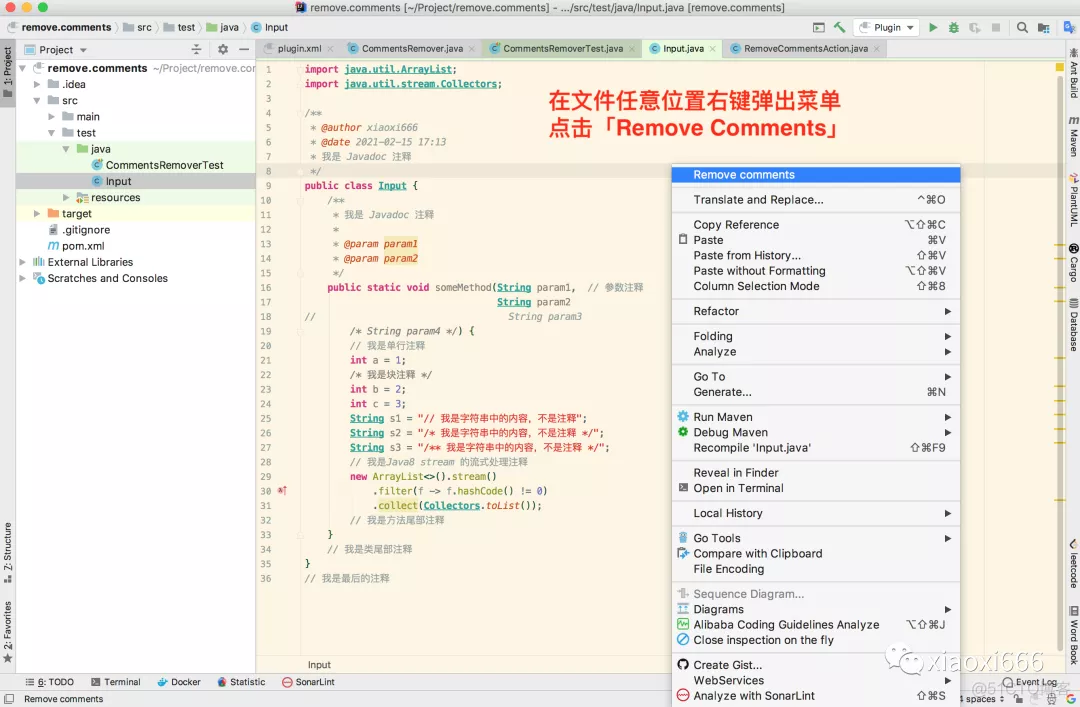
IDEA插件的原理基本都是事件驱动,如下图所示,我们创建了一个事件监听器,当检测到编辑器中点击右键后,即可弹出菜单,我们的插件在菜单中的第一个位置。
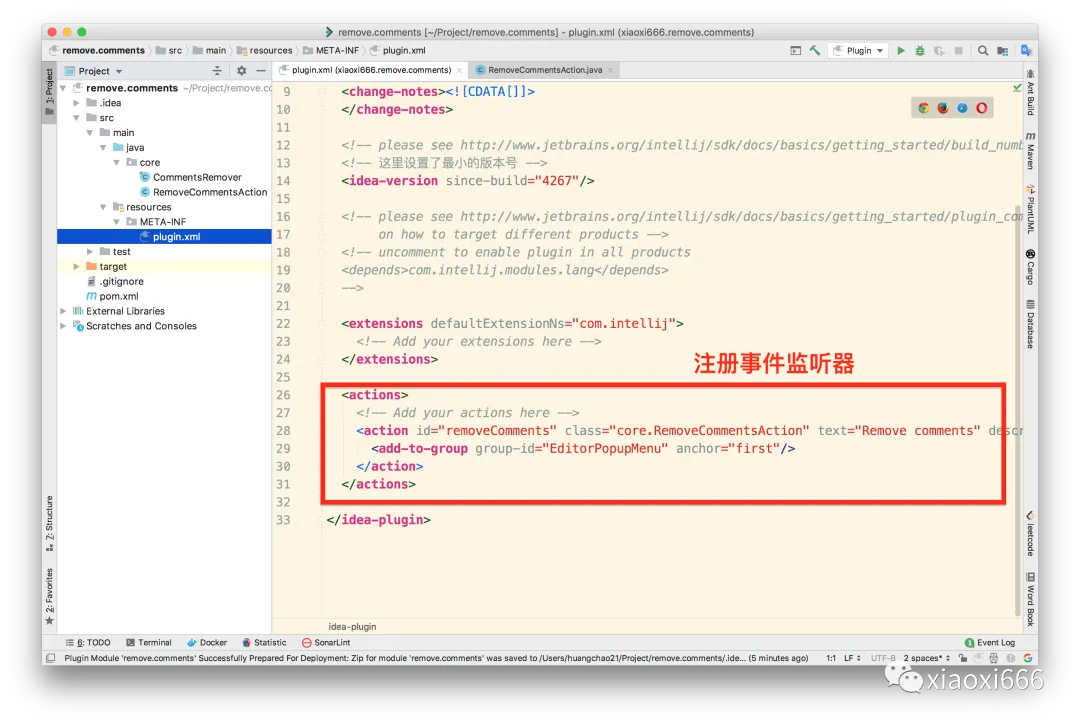
接下来,实现事件处理器:
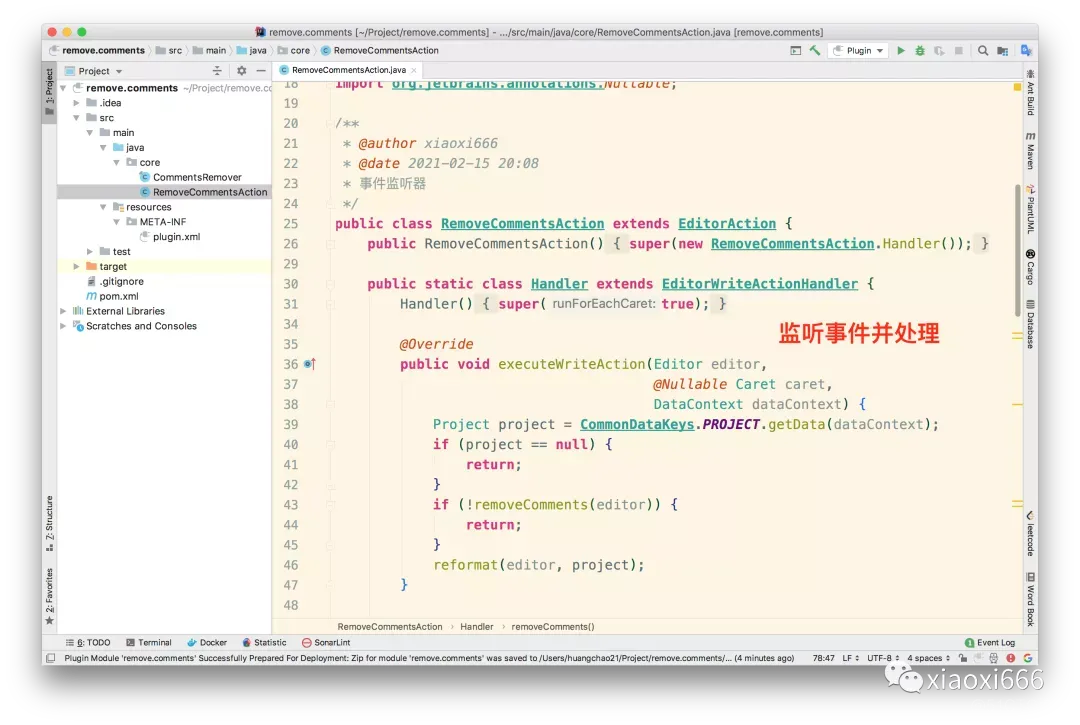
其中包含两段核心代码:
删除源码注释。首先读取当前文件内容也即源码,然后交给前面已经介绍过的CommentsRemover.doAction处理,就拿到了删除注释后的源码。
格式化代码。删除注释后,可能会引入多余的空格,因此我们自动格式化,这样用户就不用再手动格式化一次了。
/*** 移除代码中的注释** @param editor* @return true if remove comments successfully */private boolean removeComments(Editor editor) {String src = editor.getDocument().getText();if (Strings.isNullOrEmpty(src)) {return false;}String dst = CommentsRemover.doAction(checkEndLineAndModifyIfNeed(src));if (Strings.isNullOrEmpty(dst)) {return false;}editor.getDocument().setText(dst);return true;}/*** 由于我们保留了源码格式,移除注释之后会引入不必要的空格,因此需要再格式化一下** @param editor* @param project */private void reformat(Editor editor, Project project) {PsiDocumentManager.getInstance(project).commitAllDocuments();PsiFile file = PsiDocumentManager.getInstance(project).getPsiFile(editor.getDocument());if (file == null) {return;}LastRunReformatCodeOptionsProvider provider = new LastRunReformatCodeOptionsProvider(PropertiesComponent.getInstance());ReformatCodeRunOptions currentRunOptions = provider.getLastRunOptions(file);TextRangeType processingScope = TextRangeType.WHOLE_FILE;currentRunOptions.setProcessingScope(processingScope);(new FileInEditorProcessor(file, editor, currentRunOptions)).processCode();}
然后打包插件:
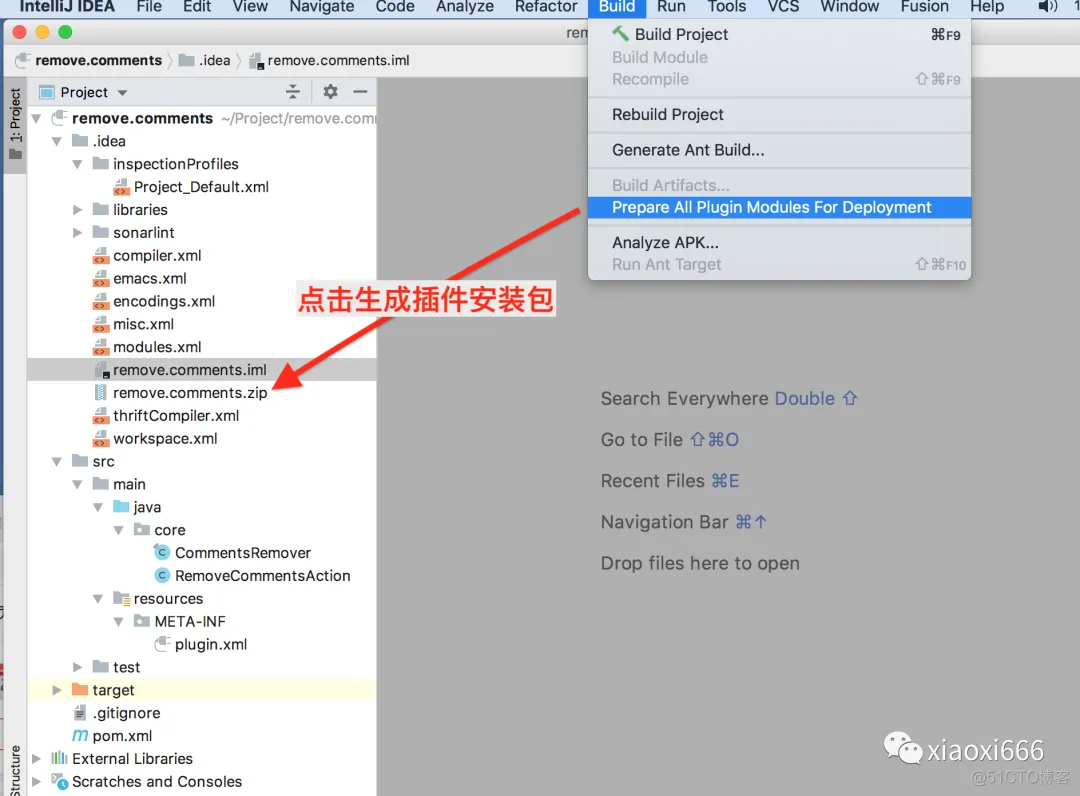
插件打包好之后,用户就可以从本地磁盘安装了:
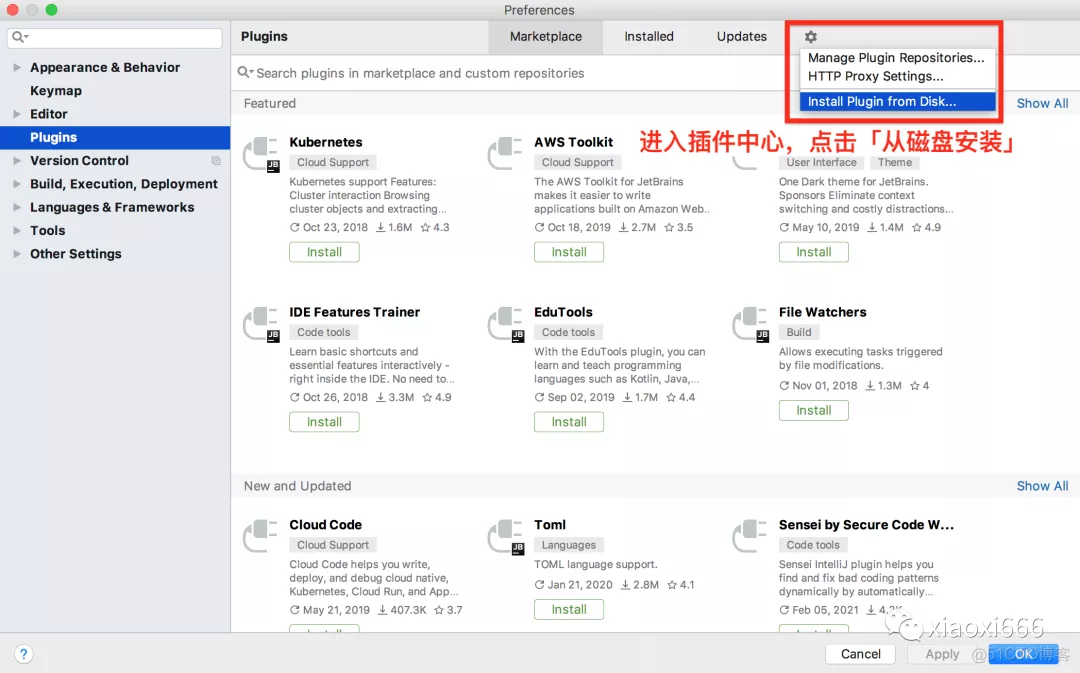
在弹出的目录树中,选中remove.comments.zip安装包,确定即可。
重启IDEA后,可以看到插件已安装成功:
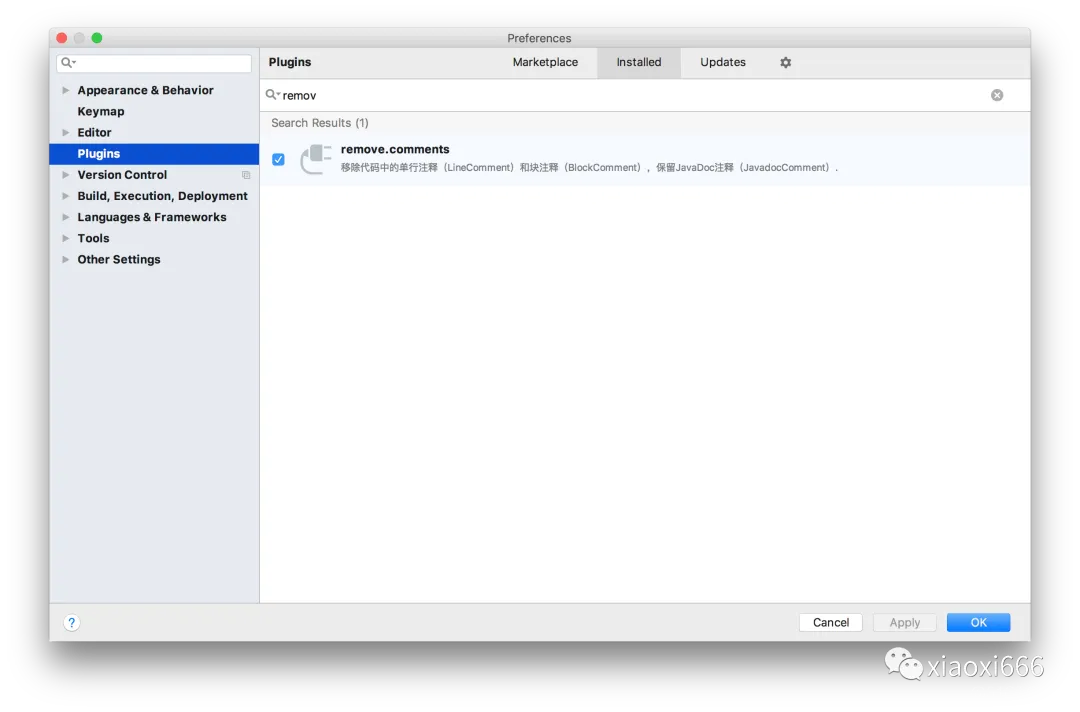
此时我们就可以使用该插件,一键删除代码中的注释了。演示一下效果:
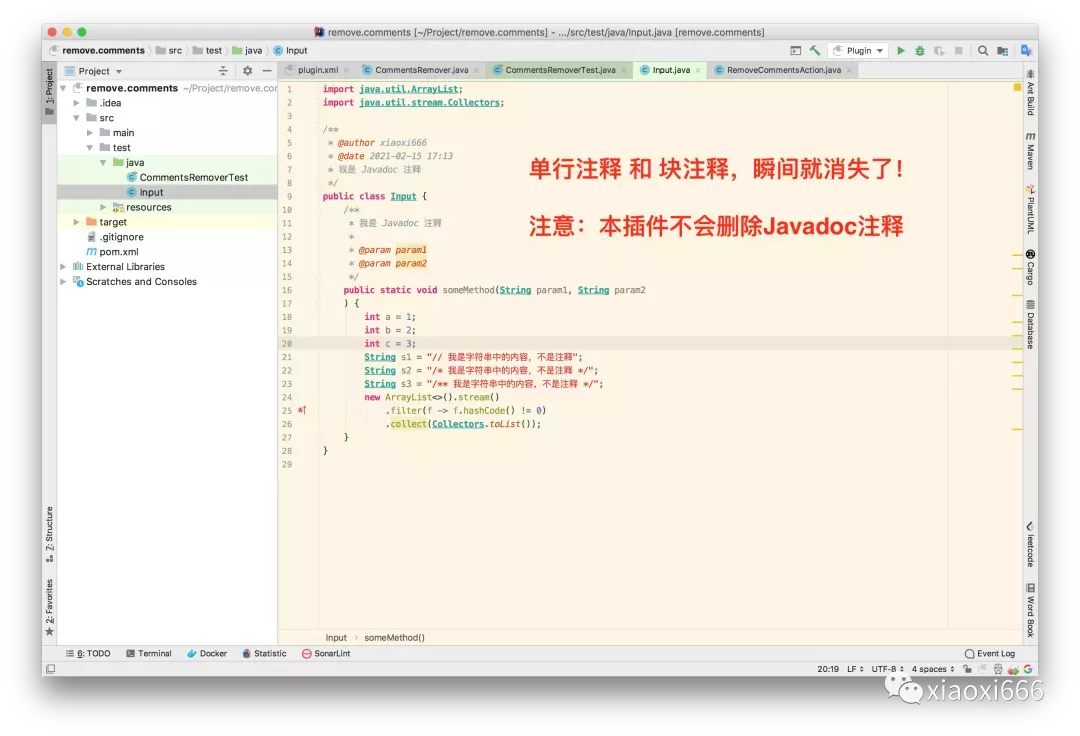
不严格性能测试(响应时间包括插件处理时间和IDEA界面更新时间):
对于500行左右的文件,响应时间约200ms,几乎瞬间完成。
对于1000行左右的文件,响应时间约为1s。
对于3000行左右的文件,响应时间约需2s。
对于5000行左右的文件,响应时间约需3s。
总之,日常使用毫无压力。
总结
本文首先介绍了若干删除注释的手段;继而介绍了一种利用第三方库JavaParser删除Java注释的思路,并加以分析和实践;最终将其封装为IDEA插件,方便其他用户使用。
另外,由于本人对JavaParser的认知不是特别深入,难免存在未考虑到的场景。若大家在使用过程中发现bug,欢迎到github提issue甚至pr。
资源
源码均已放在github:https://github.com/xiaoxi666/remove.comments。
插件也已经上传至github,可点击下载。或者关注公众号「xiaoxi666」,后台回复「删除注释」,即可收到插件下载地址。
扩展
针对文中提出的第一种状态机思路,之前也写文章介绍过。有兴趣的读者可尝试动手实现一下。

