
数据库基本概念
目录
- O r a c l e 基本概念
- O c e a n b a s e 基本介绍
- O r a c l e S Q L 基本优化
- O c e a n B a s e S Q L 基本优化
oracle基本概念
数据库和实例
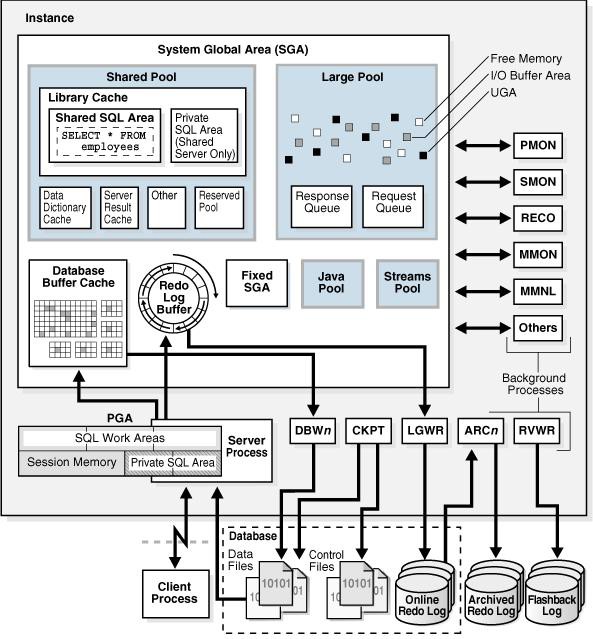
数据库实例(Database Instance)
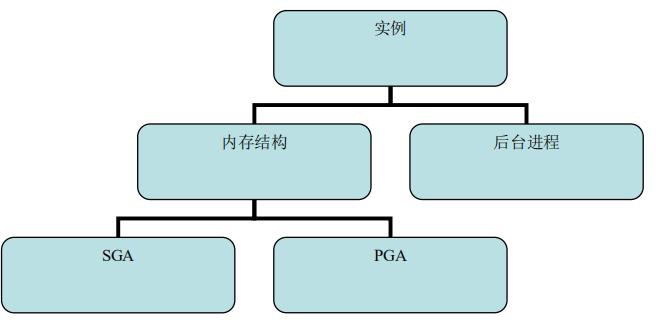
部署方式
数据库(Database)
系列物理文件(数据文件,控制文件,联机日志等)的集合或与之对应的逻辑结构(表空间,段等)被称为数据库
u物理存储结构
数据文件、重做日志文件、控制文件
u逻辑存储结构
表空间、段、区、块
表空间(TableSpace)
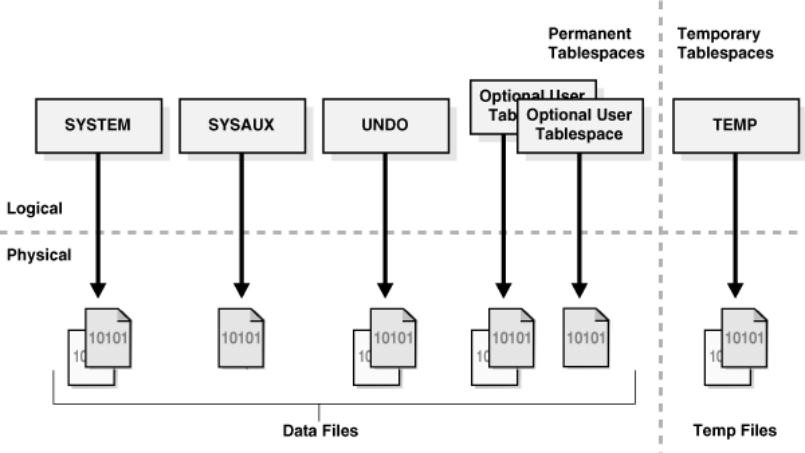
表空间、用户、表之间的关系
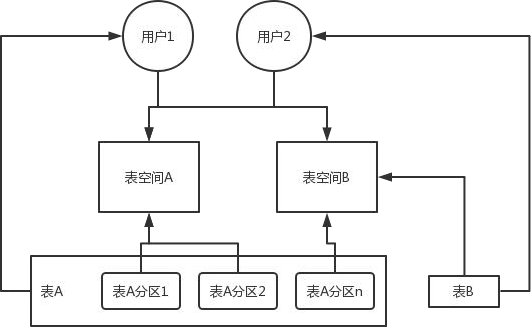
对象定义
| 描述 | |
|---|---|
| Table | 表将数据存储到行中。表是关系数据库中最重要的架构对象 |
| Indexes | 索引提供对行的直接、快速访问。Oracle 数据库支持几种类型的索引。索引组织的表是数据存储在索引结构中的表 |
| Partitions | 分区是大型表和索引的片段。每个分区都有自己的名称,可以选择有自己 的存储特征。 |
| Views | 视图是一个或多个表或其他视图中数据的查询结果。您可以将它们视为存 储的查询。 |
| Sequences | 序列是用户创建的对象。通常,使用序列生成主键值。 |
| Synonyms | 同义词是另一个架构对象的别名。由于同义词只是一个别名,因此除了在 数据字典中定义它,它不需要任何存储。 |
| PL/SQL subprograms and packages |
PL/SQL 是 SQL 的 Oracle 过程扩展。 PL/SQL 子程序是一个名为 PL/SQL块,可以使用一组参数调用。 PL/SQL 包对逻辑相关的 PL/SQL 类型、变量和子程序进行分组。 |
Oracle SQL 语句分为以类别:
数据定义语言 (DDL) 语句 CREATE ,DROP ,TRUNCATE
数据操作语言 (DML) 语句
SELECT,UPDATE、DELETE、INSERT、MERGE
事务控制语句 COMMIT,SAVEPOINT,ROLLBACK
会话控制语句 ALTER SESSION
系统控制声明
ALTER SYSTEM、ALTER DATABASE
锁(LOCK)
数据库是一个多用户使用的共享资源。当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况。若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数据库的一致性
锁(LOCK)
TM 锁(表级锁)
TM 锁用于确保在修改表的内容时,表的结构不会改变
| 锁模式 | 锁名称 | 锁描述 | SQL操作 |
|---|---|---|---|
| 1 | NULL | 无 | select |
| 2 | ss(Row-S) | 行级共享锁,其他对象只能查询这些数据 | select for update、lock for update |
| 3 | SX(Row-X) | 行级排他锁,在提交前不允许做DML操作 | Insert,update,delete |
| 4 | S(Share) | 共享锁 | create index,lock share |
| 5 | SSX(S/Row-X) | 共享行级排他锁 | |
| 6 | X(Exclusive) | 排他锁 | alter table、drop table、 truncate table、drop index |
ROWID Format

高水位线(High Water Mark, HWM)
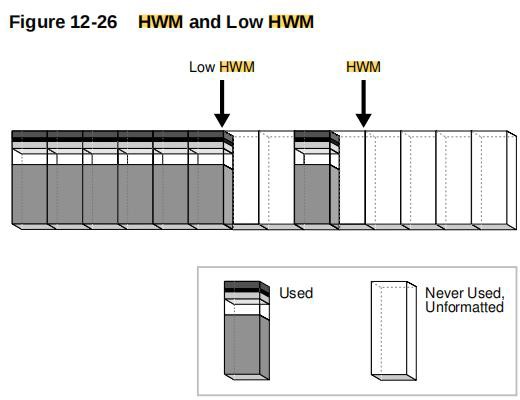
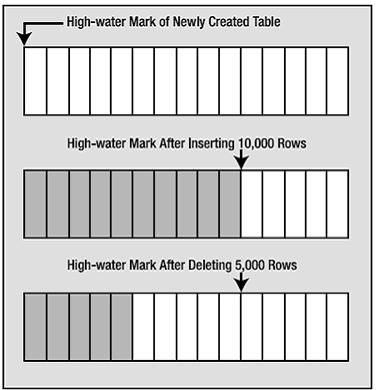 高水位线(High Water Mark, HWM)
高水位线(High Water Mark, HWM)
- 先得明白select的查询特性:select查询时候,会对表中数据进行一次扫描,并不是说数据块有多少数据就扫描多少数据,其决定因素:高水位线以下的数据。
例:新建A表,这时高水位线是0,所以这时查询速度就极快,然后A表插入1000万条数据,这时高水位已经提到了1000W的级别,再次查询的时候,对表中数据扫描就会按照实时的高水位线以下进行扫描。如果delete把数据全部删除,但是高水位线依旧在1000W的级别,查询时候仍然会按照 1000W的高水位线进行扫描。
这就是为什么有时候表中数据很少,但是查询速度很慢,其原因就是因为该表的高水位线决定的。
- 降低高水位线:使用truncate语句进行删除表中数据,相当于重新新建了表,不仅把数据清空,而且把高水位线拉低至0,适用于数据量大的临时表。
锁(LOCK)
TX 锁( 事务锁或行级锁)
TM 锁用于确保在修改表的内容时,表的结构不会改变
当事务执行数据库插入、更新、删除操作时,该事务自动获得操作表中操作行的排它锁。
事务发起第一个修改时会得到TX 锁(事务锁),而且会一直持有这个锁,直至事务执行提交(COMMIT)或回滚(ROLLBACK)
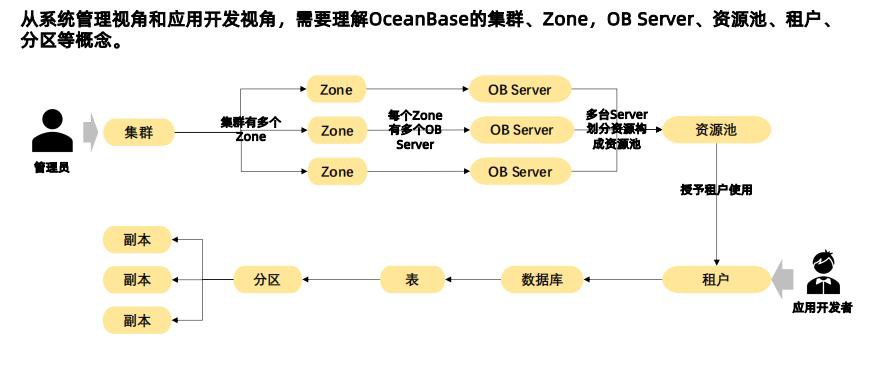
Ocean Base基本概念
OceanBase基本概念介绍
| 分类 | Oracle兼容模式 | MySQL兼容模式 |
|---|---|---|
| 数据类型 | 支持字符型、数字型、日期型、ROWID、部分 LOB类型。(NCLOB在支持中) | 支持所有整型、浮点型、日期时间、字符型、枚举型、集合类型、JSON类型。(GIS相关类 型支持中) |
| 数据库对象 | 支持普通表、视图(只读、可更新)、临时表、同义词、identity column、B树索引、表和索引分区(二级分区、模板非模板、分区方式全兼容)、序列、DBLink、所有类型约束。(OB到 Oracle Dblink、interval分区在支持中) |
完整支持MySQL兼容的数据库对象,包括表,索引,视图,约束、分区类型。 |
| SQL语法 | 支持ANSI标准SQL语法、MERGE INTO、 INSERT ALL、ERROR LOGGING、SELECT FOR UPDATE、 集合操作、FETCH子句、关联 与非关联子查询、CTE |
支持ANSI标准SQL语法,INSERT ON DUPLICATED KEY UPDATE、INSERT IGNORE、LOAD DATA、 REPLACE、关联与 非关联子查询等。 |
| 过程语言与触发器 | 支持PL*SQL兼容能力,支持行触发器(包括 instead of触发器)、语句触发器。(多维数组、 条件编译、系统触发器在支持中) |
支持MySQL兼容的过程语言;支持MySQL 5.6兼容的触发器。 |
| 内建函数及系统包 | 支持 95% 以上的Oracle 内置通用运算函数、分析函数等, 支持通用系统包中的绝大部分函 数及方法。(其他函数及系统包在支持中)。 |
完整支持MySQL运算符、通用运算函数, JSON相关函数。(GIS相关函数在支持中) |
| 客户端驱动 | 支持c,java,ODBC驱动;支持OCI兼容的c语言库,Pro*C兼容的预编译器。(其他语言驱动在计划中; c语言库函数和编译器方法在完善中 | MySQL协议全兼容,支持MySQL生态的客户端。 |
| 安全 | 支持完整的系统权限,对象权限,角色,数据库审计,存储加密(TDE) , 行访问控制(label security)(细粒度访问控制VPD在支持中) |
支持MySQL兼容的对象权限,存储加密(TDE) (暂不支持MySQL 8.0的角色权限) |

表组(Table Group)
对经常会被同时访问的一组表,为了优化性能,需要将它们相同类型的副本存储在同一个
OceanBase 数据库服务器中。通过定义一个 Table group,并且将这一组表放在这个 Table
group 中来达到这个目的。此外,同一个 Table group 的多个分区表具有相同的分区数和分
区规则。假设一个 Table group 里的表都有 N 个分区,所有这些表的第 i
个分区的集合组成
一个 Partition group。同一个 Partition group 里的分区,主副本总是位于同一个 Server
上。
OBProxy
OceanBase 数据库高性能反向代理服务器,它接收客户端的应用请求,并转发给OBServer,然后 OBServer 将数据返回给 OBProxy,OBProxy 将数据转发给应用客户端。具有防连接闪断、屏蔽后端异常(宕机、升级、网络抖动)、MySQL 协议兼容、强校验、支持热升级和多集群等功能。
Zone
是 Availability Zone 的缩写。
一个 OceanBase 集群由若干个 Zone 组成。Zone 的含义是可用性区,通常指一个机房(数据中心或 IDC)。为了数据的安全和高可用性,一般会把数据的多个副本分布在多个 Zone上。这样,对于 OceanBase 数据库来说,可以实现单个 Zone 的故障不影响数据库服务。一个 Zone 包括若干物理服务器。
租户(Tenant)
OceanBase 数据库通过租户实现资源隔离,采用单集群多租户的管理模式。OceanBase 集群的一个租户相当于一个 MySQL 或者 Oracle 的实例。OceanBase 数据库的租户之间的资源
和数据都是隔离的。租户拥有一组计算和存储资源,提供一套完整独
立的数据库服务。
OceanBase 数据库上有系统租户和普通租户。系统租户下存放 OceanBase 数据库管理的各种内部元数据信息;普通租户下存放用户的各种数据和数据库元信息。
Oracle SQL基本优化
什么是好的SQL语句
- 尽量简单,模块化
- 易读、易维护
- 节省资源
内存 CPU
扫描的数据块要少少排序
- 不造成死锁
SQL优化的一般性原则
- 目标:
减少服务器资源消耗(主要是磁盘IO);
- 设计方面:
合适的索引;表分区技术;
- 编码方面:
利用索引,避免大表FULL TABLE SCAN;合理使用临时表;
避免写过于复杂的sql,不一定非要一个sql解决问题;在不影响业务的前提下减小事务的粒度;
使用绑定变量。
SQL语句优化过程
- 定位有问题的语句
- 检查执行计划
- 检查执行过程中优化器的统计信息
- 分析相关表的记录数、索引情况
- 改写SQL语句、使用HINT、调整索引、表分析
- 有些SQL语句不具备优化的可能,需要优化处理方式
- 达到最佳执行计划
索引
索引是建立在表的一列或多个列上的辅助对象,目的是加快访问表中的数据
索引基本分为以下几种:B*Tree索引,反向索引,降序索引,位图索引,函数索引,interMedia全文索引等,其中最常用的是B*Tree索引和Bitmap索引
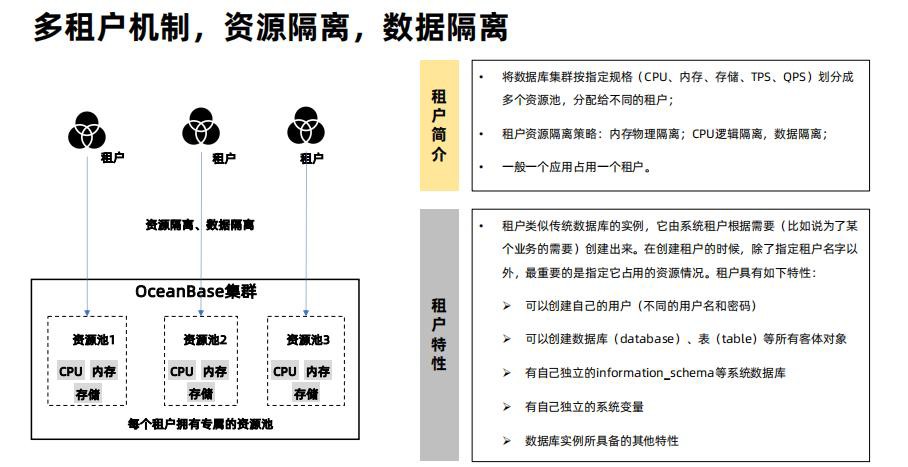
B-Tree 索引
B-Tree索引是最常见的索引结构,默认建立的索引就是这种类型的索引。B-Tree索引在检索有很多不同的值数据列时提供了最好的性能。
DML语句:
Create index indexname on tablename(columnname[columnname…])
B-tree特性:
- 适合与大量的增、删、改(OLTP);
- 不能用包含OR操作符的查询;
- 适合高基数的列(唯一值多);
- 典型的树状结构;
- 每个结点都是数据块;
- 叶子块数据是排序的,从左向右递增;
- 在分支块和根块中放的是索引的范围。
B-Tree 索引
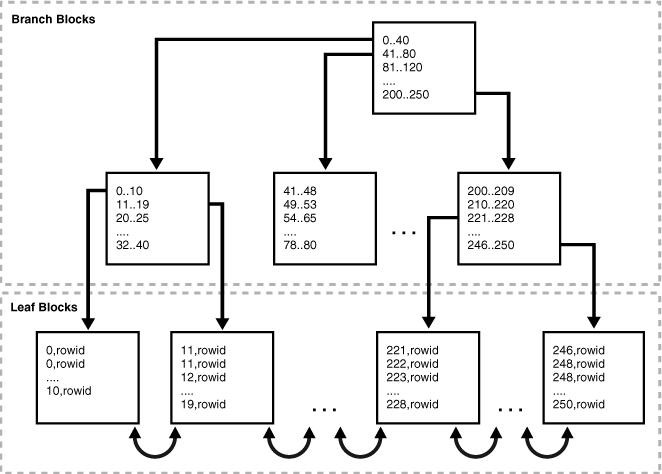
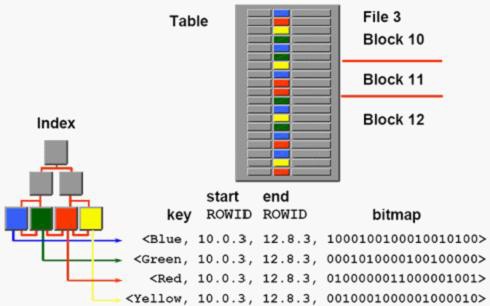
Bitmap位图索引
位图索引主要用于决策支持系统或静态数据,不支持行级锁定。位图索引最好用于重复值很多的列。
DML语句:
Create BITMAP index indexname on tablename(columnname[columnname…])
Bitmap特性:
适合与决策支持系统;做UPDATE代价非常高;
非常适合OR操作符的查询;
Bitmap位图索引
位图索引主要针对大量相同值的列而创建
索引为何失效?
- 对索引字段进行计算
- 对索引字段使用了函数(to_date,to_char)
- 索引字段与数据类型不符合
- 不等于符号
- Is null / is not null
- 查询数据选取范围过大
三种连接方式
排序合并连接(sort merge join):
是集合的合并操作,一般是在没有有效的索引时使用循环嵌套连接(nested loop join):
是一种循环的行操作,对于事务型处理是首选。在OLTP系统中常见,使用有效的索引来执行操作。
散列连接(hash join):
使用连接表的全表扫描完成。Oracle执行每个表的全表扫描,并根据内存情况,将每个表分成所需的多散列分区,然后通过另一个表的相应分区试探这个散列表。散列连接适合大表的连接。
管理统计信息
- 使用 DBMS_STATS 包:
- GATHER_TABLE_STATS —表统计信息
- GATHER_INDEX_STATS —索引统计信息
- GATHER_SCHEMA_STATS —用户统计信息
- GATHER_DATABASE_STATS —数据库统计信息
海量数据库设计的关键技术 —- 分区
- 性能
- Select和DML操作只访问指定分区
- 并行DML操作
- Partition-wise Join
- 可管理性:数据删除,数据备份
- 历史数据清除
- 提高备份性能
- 指定分区的数据维护操作
- 可用性
- 将故障局限在分区中
- 缩短恢复时间
- 分区目标优先级
- 高性能
- 数据维护能力
- 实施难度
- 高可用性(故障屏蔽能力)
- 性能
201

 5
5




按年度进行分区
帐户交易明细表
201
6
201
 7
7
201
8
范围分区特点
- Range分区通过对分区字段值的范围进行分区
- Range分区特别适合于按时间周期进行数据的存储。日、周、月、年等。
- 数据管理能力强
- 数据迁移
- 数据备份
- 数据清理
- 范围分区的数据可能不均匀
- 范围分区与记录值相关,实施难度和可维护性相对较差
Hash分区特点
- 基于分区字段的HASH值,自动将记录插入到指定分区。
- 分区数一般是2的N次方
- 易于实施
- 总体性能最佳
- 适合于静态数据
- HASH分区适合于数据的均匀存储
- 数据管理能力弱
- HASH分区对数据值无法控制
列表分区特点
- List分区通过对分区字段的离散值进行分区。
- List分区是不排序的,而且分区之间没有关联关系
- List分区适合于对数据离散值进行控制。
- List分区只支持单个字段。
- List分区具有与范围分区相似的优缺点
- 数据管理能力强
- List分区的数据可能不均匀
- List分区与记录值相关,实施难度和可维护性相对较差
复合分区例
create table daily_trans_data (…column definitions …) partition by range(trans_datetime)
subpartition by hash(customer_no) subpartitions 8 store in (dtd_data01,dtd_data02)
(partition dtd_20010620 values less than (to_date(‘21-jun-2001’,’dd-mon-yyyy’)) (subpartition dtd_20010620_s01
,subpartition dtd_20010620_s02
,subpartition dtd_20010620_s03 tablespace dtd_data03
,subpartition dtd_20010620_s04 tablespace dtd_data04
,subpartition dtd_20010620_s05 tablespace dtd_data05
,subpartition dtd_20010620_s06 tablespace dtd_data06
,subpartition dtd_20010620_s07 tablespace dtd_data07
,subpartition dtd_20010620_s08 tablespace dtd_data08
)
,partition dtd_20010621 values less than (to_date(‘22-jun-2001’,’dd-mon-yyyy’))
,partition dtd_20010622 values less than (to_date(‘23-jun-2001’,’dd-mon-yyyy’)) subpartitions 4)
系统进程查SQL语句
SELECT
t.SQL_FULLTEXT, —sql语句 p.SPID, —系统进程号 s.SID,
s.SERIAL#, s.SQL_ID, p.PID
FROM v$session s, v$process p, v$sqlarea t WHERE s.PADDR = p.ADDR
and s.SQL_ID = t.SQL_ID
and p.SPID =’9375’; —系统进程号
锁表语句查询
select a.sid,
a.serial#, p.spid, c.object_name, b.session_id,
b.oracle_username, b.os_user_name
from v$process p, v$session a, v$locked_object b, all_objects c where p.addr = a.paddr
and a.process = b.process and c.object_id = b.object_id
and c.OBJECT_name = ‘TABLE_NAME’;
Ocean Base SQL基本优化
单条 SQL 调优
场景 sql调优关注点
单表访问 l 访问路径是否开启索引扫描。 使用索引扫描可以减小数据的访问量。
l 是否创建合适的索引。 使用索引排序以减少排序或聚合等耗时操作。
l 分区裁剪是否正确。 适当的分区条件可以减少不必要的分区访问。
l 是否提高查询的并行度。 分区数目较多时,通过提高并行度以更多资源的代价获取单条 SQL 查询的性能提升。
多表访问 不仅要关注单表的 SQL 调优问题,还要关注如下多
表间的联接问题:
l 联接顺序
l 联接算法
l 跨机或并行联接的数据再分布方式
l 查询改写
SQL 调优基本流程
在 SQL 调优中,针对慢 SQL 的分析步骤如下:
1、通过全局 SQL 审计表 (g)v$sql_audit 、 SQL Trace 和计划缓存视图查看 SQL 执行性能信息,初步查找 SQL 请求的流程中导致耗时或消耗资源(如内存、磁盘 IO 等)的 SQL。
2、单条 SQL 的执行性能往往与该 SQL 的执行计划相关,因此,执行计划的分析是最重要的手段。通过执行 EXPALIN 命令查看优化器针对给定 SQL 生成的逻辑执行计划,确定可能的调优方向
3、收集 SQL 中涉及到的表、列、谓词等对象的统计信息。统计信息是代价模型中选取最优执行计划的关键,优化器可以利用统计信息来优化计划的选择策略
4、找到具体的慢 SQL,为了使某些 SQL 的执行时间或资源消耗符合预期,常见的优化方式如
下:
l 对 SQL 做等价改写生成最佳执行计划
l 针对多表访问的 SQL,还需要关注多表间的联接问题,通过优化访问路径、联接顺序和联接算法等实现查询优化
OceanBase 数据库执行计划中的各列的含义如下:
| 列名 | 含义 |
|---|---|
| ID | 执行树按照前序遍历的方式得到的编号(从 0 开始)。 |
| OPERATOR | 操作算子的名称。 |
| NAME | 对应表操作的表名(索引名)。 |
| EST. ROWS | 估算该操作算子的输出行数。 |
| COST | 该操作算子的执行代价(微秒)。 |
并行查询
并行查询是指通过对查询计划的改造,提升对每一个查询计划的 CPU 和 IO 处理能力,从而缩短单个查询的响应时间。并行查询技术可以用于分布式执行计划,也可以用于本地查询计划。当单个查询的访问数据不在同一个节点上时,需要通过数据重分布的方式,将相关的数据分布到相同的节点进行计算。以每一次的数据重分布节点为上下界,OceanBase 数据库的执行计划在垂直方向上被划分为多个 DFO(Data Flow Object),而每一个 DFO 可以被切分为指定并行度的任务,通过并发执行以提高执行效率。
一般来说,当并行度提高时,查询的响应时间会缩短,更多的 CPU、IO 和内存资源会被用于执行查询命令。对于支持大数据量查询处理的 DSS(Decision Support Systems)系统或者数据仓库型应用来说,查询时间的提升尤为明显。
整体来说,并行查询的总体思路和分布式执行计划有相似之处,即将执行计划分解之后,将执行计划的每个部分由多个执行线程执行,通过一定的调度的方式,实现执行计划的 DFO 之间的并发执行和 DFO 内部的并发执行。并行查询特别适用于在线交易(OLTP)场景的批量更新操作、创建索引和维护索引等操作。
当系统满足以下条件时,并行查询可以有效提升系统处理性能:充足的 IO 带宽
系统 CPU 负载较低充足的内存资源
如果系统没有充足的资源进行额外的并行处理,使用并行查询或者提高并行度并不能提高执行性能。相反,在系统过载的情况下,操作系统会被迫进行更多的调度,例如,执行上下文切换或者页面交换,可能会导致性能的下降。
THANKS

