
国产数据库介绍
目录/ C O N T E N T S
TDSQL GaussDB
Oceanbase GoldenDB
01
TDSQL
兼容性
- 完全兼容MYSQL 5.x 和8.x版本的语法、函数、数据类型
- 未针对oracle做兼容优化
主持人笔记
2023-08-08 01:15:39
-—————————————————————-
TDQL是基于MYSQL基础上开发的国产数据库,完全兼容MYSQL语法和特性。
表类型
主持人笔记
2023-08-08 01:15:39
-—————————————————————-
在分布式实例中,如果两张表分表键相等,这意味着,两张表相同的分表键对应的行,一定存储于相同的物理节点组中。这种场景通常被称为组拆分(groupshard),会极大提高业务联合查询等语句的处理效率。由于单表默认放置在第一个 set 上,如果在分布式实例中建立了大量的单表,则会导致第一个 set 的负载太大。
除特殊情况外,建议在分布式实例中尽量都使用分表。
- 分表:即水平拆分表,该表从业务视角是一张完整的逻辑
表,但后端根据分表键(shardkey)的 HASH 值将数据
分布到不同的节点(set)中。
- 单表:又名 Noshard 表,无需拆分,且没有做任何特殊处理的表,目前分布式实例将该表默认存放在第一个物理节点组(set)中。
- 广播表:又名小表广播技术,即设置为广播表后,该表的
所有操作都将广播到所有节点(set)中,每个 set 都有
该表的全量数据,常用于业务系统的配置表等。
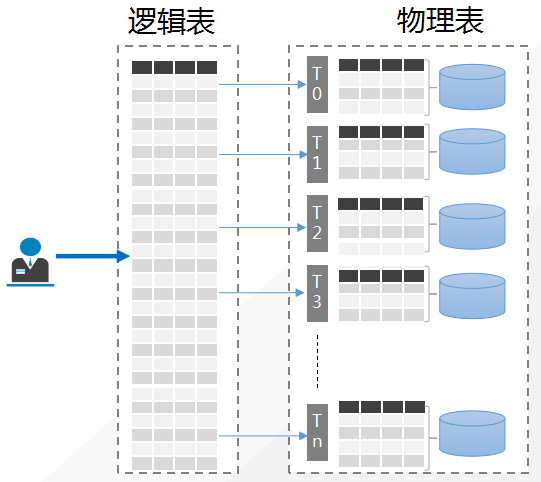
水平分表
在 TDSQL MySQL版 中,数据的切分通常就需要找到一个分表键
(shardkey)以确定拆分维度,再采用某个字段求模(HASH)的方案进行分表,而计算 HASH 的某个字段就是 shardkey。 HASH 算法能够基本保证数据相对均匀地分散
在不同的物理设备中。
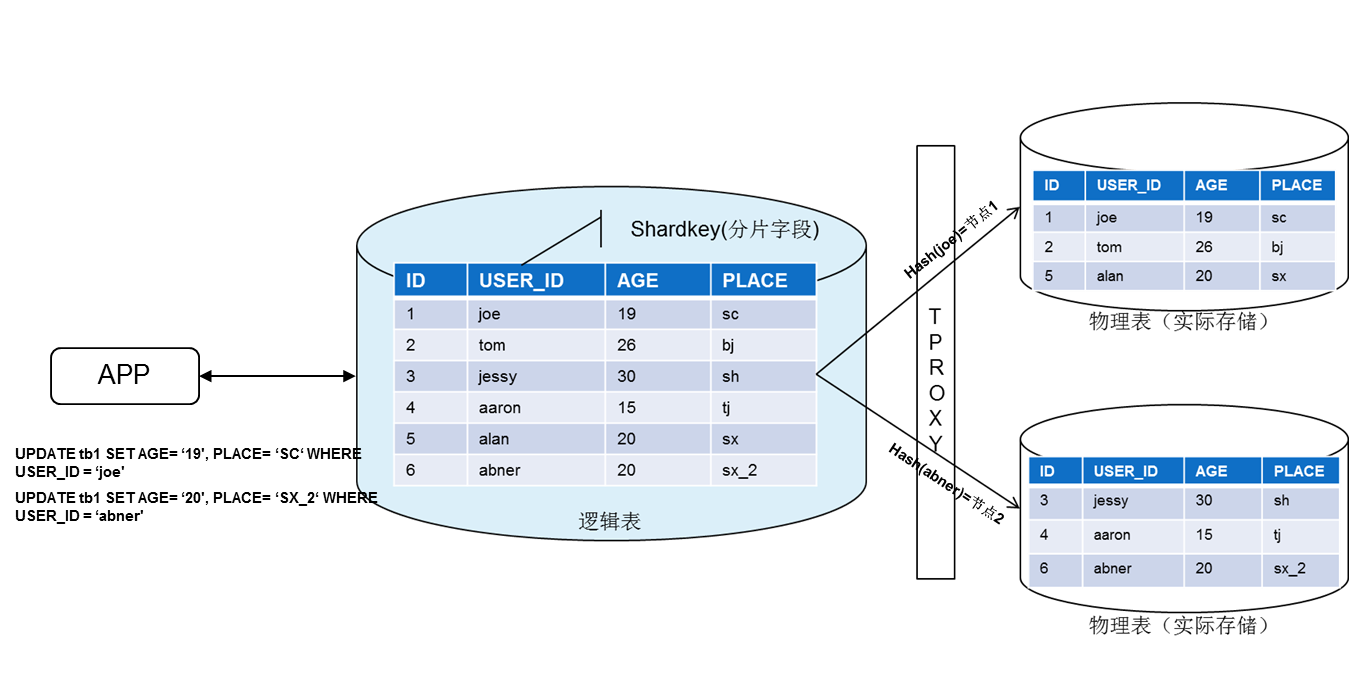
写入数据( SQL 语句含有 shardkey )
主持人笔记
2023-08-08 01:15:40
-—————————————————————-
业务写入一行数据。
网关对 shardkey 进行 hash,得出 shardkey 的 hash 值。不同的 hash 值范围对应不同的分片(调度系统预先分片的算法决定)。
数据根据分片算法,将数据存入实际对应的分片中。
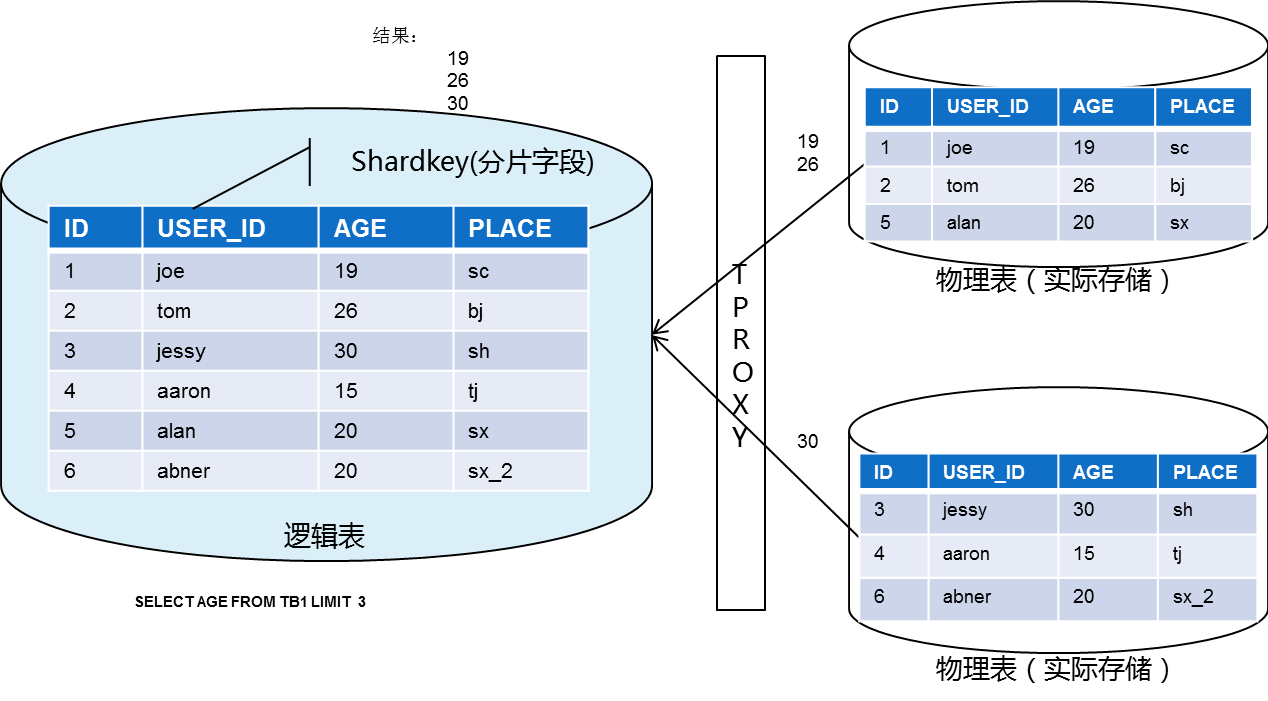
读取数据
主持人笔记
2023-08-08 01:15:40
-—————————————————————-
读取数据(有明确 shardkey 值)
业务发送 select 请求中含有 shardkey 时,网关通过对 shardkey 进行 hash。不同的 hash 值范围对应不同的分片。
数据根据分片算法,将数据从对应的分片中取出。
读取数据(无明确 shardkey 值)
业务发送 select 请求没有 shardkey 时,将请求发往所有分片。各个分片查询自身内容,发回 Proxy 。
Proxy 根据 SQL 规则,对数据进行聚合,再答复给网关。
使用限制
大特性限制
不支持自定义函数、事件、表空间
不支持视图、存储过程、触发器、游标不支持外键、自建分区
不支持复合语句,如 BEGIN END、LOOP
不支持主备同步相关的 SQL
小语法限制
不支持 CREATE TABLE … SELECT
不支持 CREATE TEMPORARY TABLE
不支持 CREATE/DROP/ALTER SERVER/LOGFILE GROUP
不支持 ALTER 对分表键(shardkey)进行改名
常用 DML
select
建议带上 shardkey 字段,proxy 根据该字段的 hash 值直接将 SQL 请求路由至对应的数据库实例进行处理;否则就需要发送给集群中所有的数据库实例执行,然后 proxy 根据数据库返回的结果集进行聚合,影响执行效率。
insert/replace
字段必须包含 shardkey,否则会拒绝执行该 SQL,因为 proxy 不知道将该 SQL 发往哪个后端数据库。
delete/update
使用分表时,为安全考虑,执行该类 SQL 时,必须带有 where 条件,否则拒绝执行该 SQL
命令
建分表
create table test1 ( a int, b int, c char(20),primary key (a,b),unique key u_1(a,c) ) shardkey=a;
因为主键索引或者 unique key 索引意味着需要全局唯一,而要实现全局唯一索引,则必须包含
shardkey 字段。
除上面的限制外,shardkey 字段还有如下要求:
- shardkey 字段的类型必须是 int、bigint、smallint、char、varchar。
- shardkey 字段类型为 char、varchar 时需定义字段长度。
- shardkey 字段的值不能有中文,proxy 不会转换字符集,因此不同字符集可能会路由到不同的分区。
- 不能 update shardkey 字段的值。
- shardkey=a 放在 SQL 的最后面。
- 访问数据尽量都带上 shardkey 字段,非强制要求,但是不带 shardkey 的 SQL 会路由到所有节点,
消耗较多资源。
建广播表
支持建小表(广播表),此时该表在所有 set 中都是全量数据,主要方便于跨 set 的 join 操作,同时通过分布式事务保证修改操作的原子性,使得所有 set 的数据完全一致。
create table global_table ( a int, b int key) shardkey=noshardkey_allset;
建单表
支持建立普通的表,语法和 MySQL 完全一致,此时该表的数据全量存在第一个 set 中,所有该类型的表都放在第一个 set 中。
create table noshard_table ( a int, b int key);
连接方式
Windows 客户端连接
标准的 MySQL 客户端,例如 MySQL Workbench 、SQLyog 等
JDBC 驱动连接
在 MySQL 官网 下载一个 JDBC 的 jar 包,将其导入 Java 引用的
Library 中。
调用 JDBC 代码如下:
public static final String url = “内外网地址”;
public static final String name = “com.mysql.jdbc.Driver”; //调用 JDBC
驱动
public static final String user = “用户名”; public static final String password = “密码”;
//JDBC
Class.forName(“com.mysql.jdbc.Driver”);
Connection conn=DriverManager.getConnection(“url, user, password”);
// conn.close();
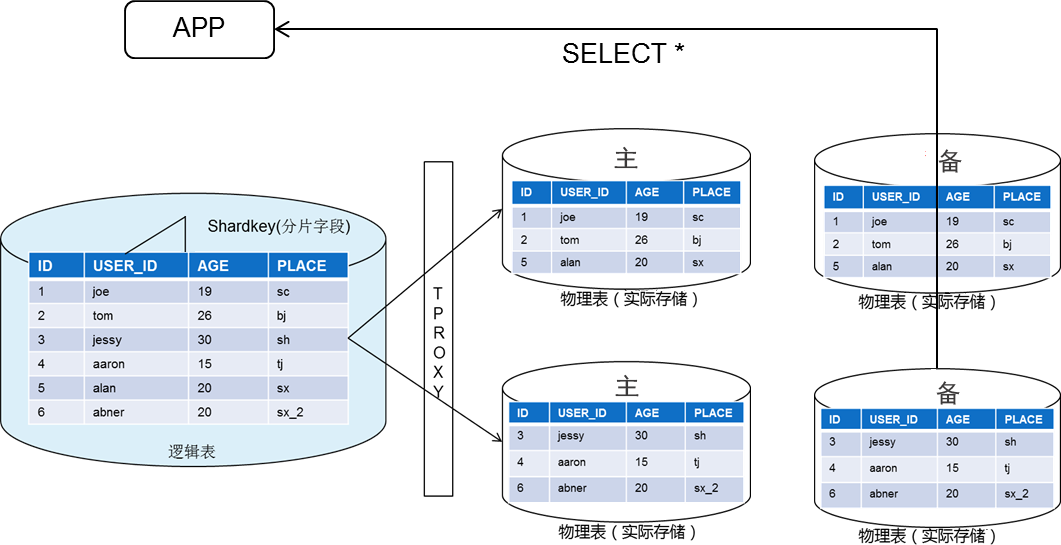
读写分离
主持人笔记
2023-08-08 01:15:41
-—————————————————————-
当处理大数据量读请求的压力大、要求高时,可以通过读写分离功能将读的压力分布到各个从节点上。
TDSQL MySQL版 默认支持读写分离功能,架构中的每个从机都能支持只读能力,如果配置有多个从机,将由网关集群(TProxy)自动分配到低负载从机上,以支撑大型应用程序的读取流量。
读写分离基本的原理是让主节点(Master)处理事务性增、改、删操作(INSERT、UPDATE、DELETE),让从节点(Slave)处理查询操作(SELECT)。只读帐号是一类仅有读权限的帐号,默认从数据库集群中的从机(或只读实例)中读取数据。
通过只读帐号,对读请求自动发送到备机,并返回结果。
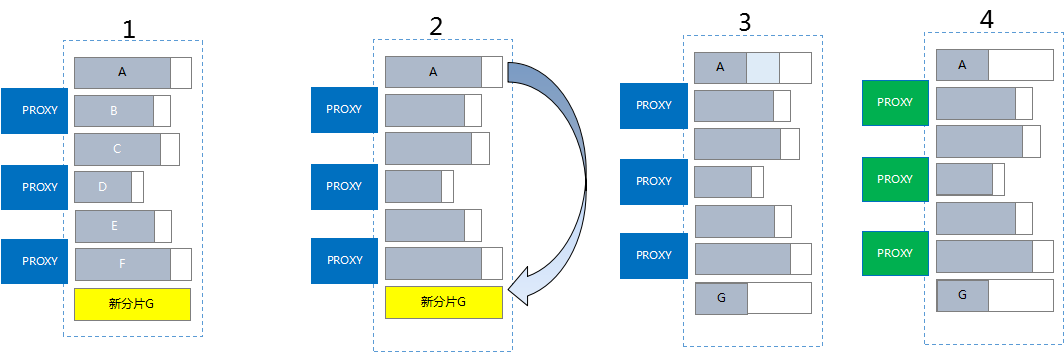
弹性扩展
新增分片扩容
- 在 TDSQL MySQL版控制台 对需要扩容的 A 节点进行扩容操作。
- 根据新加 G 节点配置,将 A 节点部分数据搬迁(从备机)到 G 节点。
- 数据完全同步后,A、G 节点校验数据库,存在一至几十秒的只读,但整个服务不会停止。
- 调度通知 proxy 切换路由。
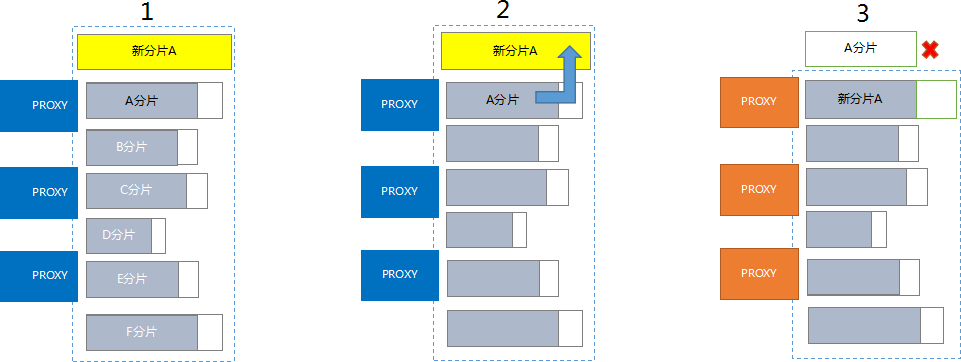
弹性扩展
现有分片扩容
- 按需要升级的配置分配一个新的物理分片(以下简称新分片)。
- 将需要升级的物理分片(以下简称老分片)的数据、配置等同步数据到新分片中。
- 同步数据完成后,在腾讯云网关做路由切换,切换到新分片继续使用。
主持人笔记
2023-08-08 01:15:41
-—————————————————————-
基于现有分片的扩容没有增加分片,不会改变划分分片的逻辑规则和分片数量
数据导出、导入工具
备份数据
./mydumper —host=10.9.4.11 —port=15003 —user=scms_aft —password=Pwdaft -E -R -G
-N —outputdir=/root/bak0609 -B scms_aft
恢复数据
./myloader —host=10.9.4.11 —port=3306 —user=scms_aft —password=Pwdaft —
directory=/root/bak0609 —enable-binlog -B scms_aft -s scms_aft
02
GaussDB
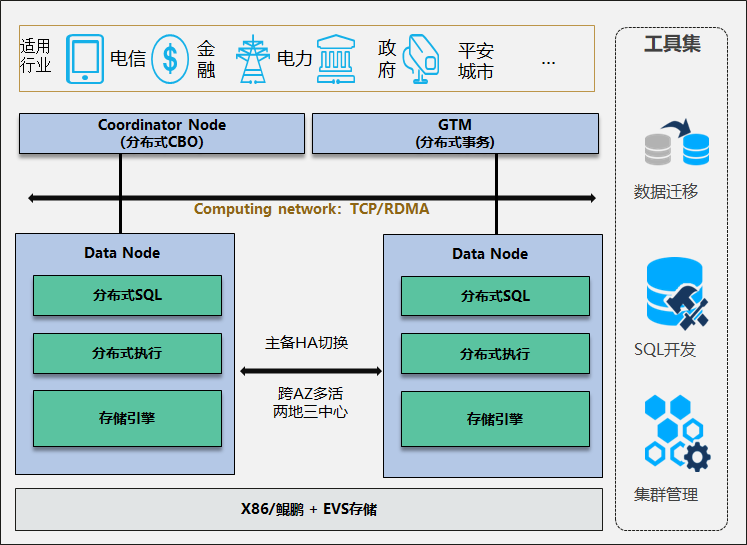
GaussD B分布式形态整
体架构
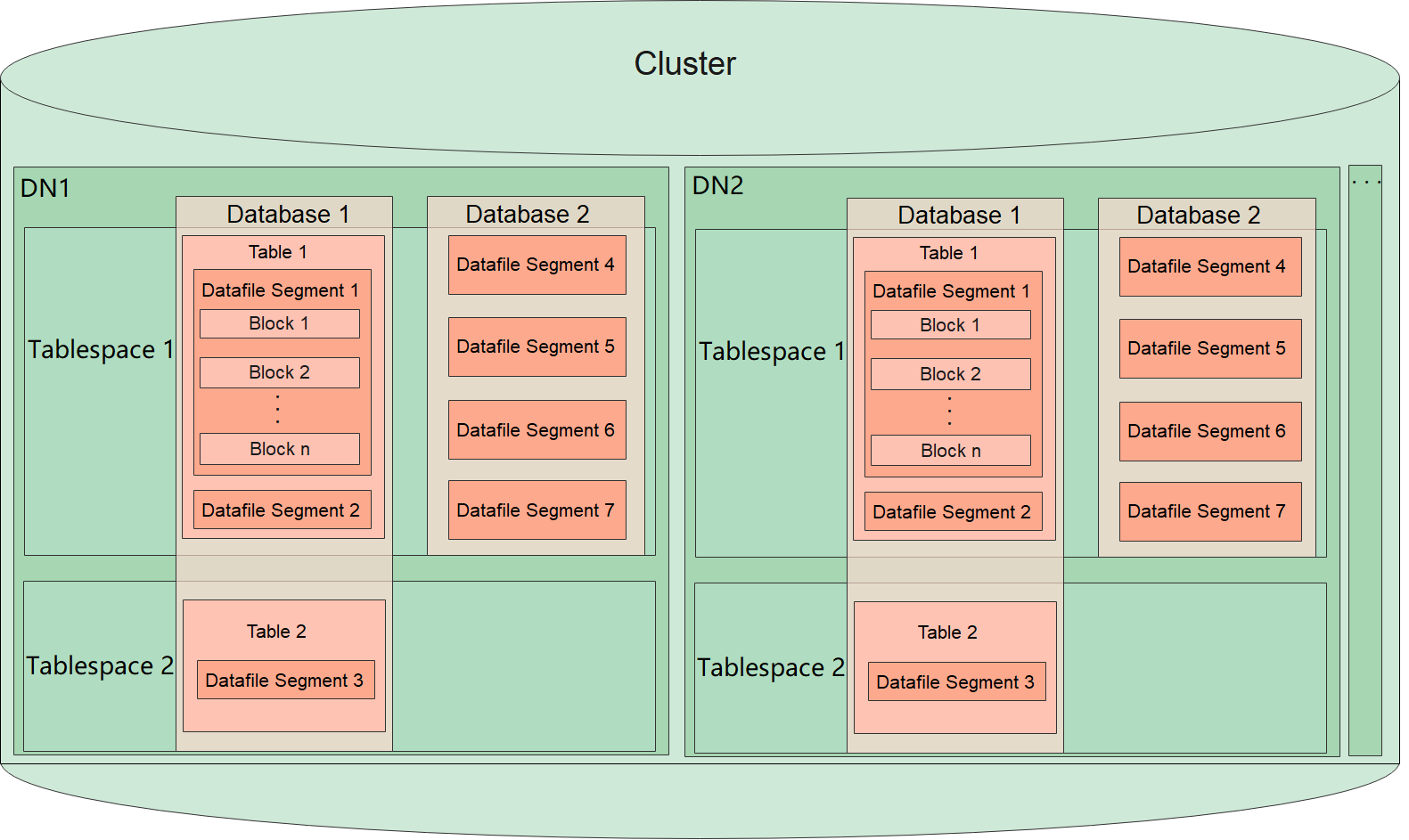
数据库逻辑结构图
主持人笔记
2023-08-08 01:15:42
-—————————————————————-
Tablespace,即表空间,是一个目录,可以存在多个,里面存储的是它所包含的数据库的各种物理文件。每个表空间可以对应多个Database。 Database,即数据库,用于管理各类数据对象,各数据库间相互隔离。数据库管理的对象可分布在多个Tablespace上。 Datafile Segment,即数据文件,通常每张表只对应一个数据文件。如果某张表的数据大于1GB,则会分为多个数据文件存储。
Table,即表,每张表只能属于一个数据库,也只能对应到一个Tablespace。每张表对应的数据文件必须在同一个Tablespace中。 Block,即数据块,是数据库管理的基本单位,默认大小为8KB。
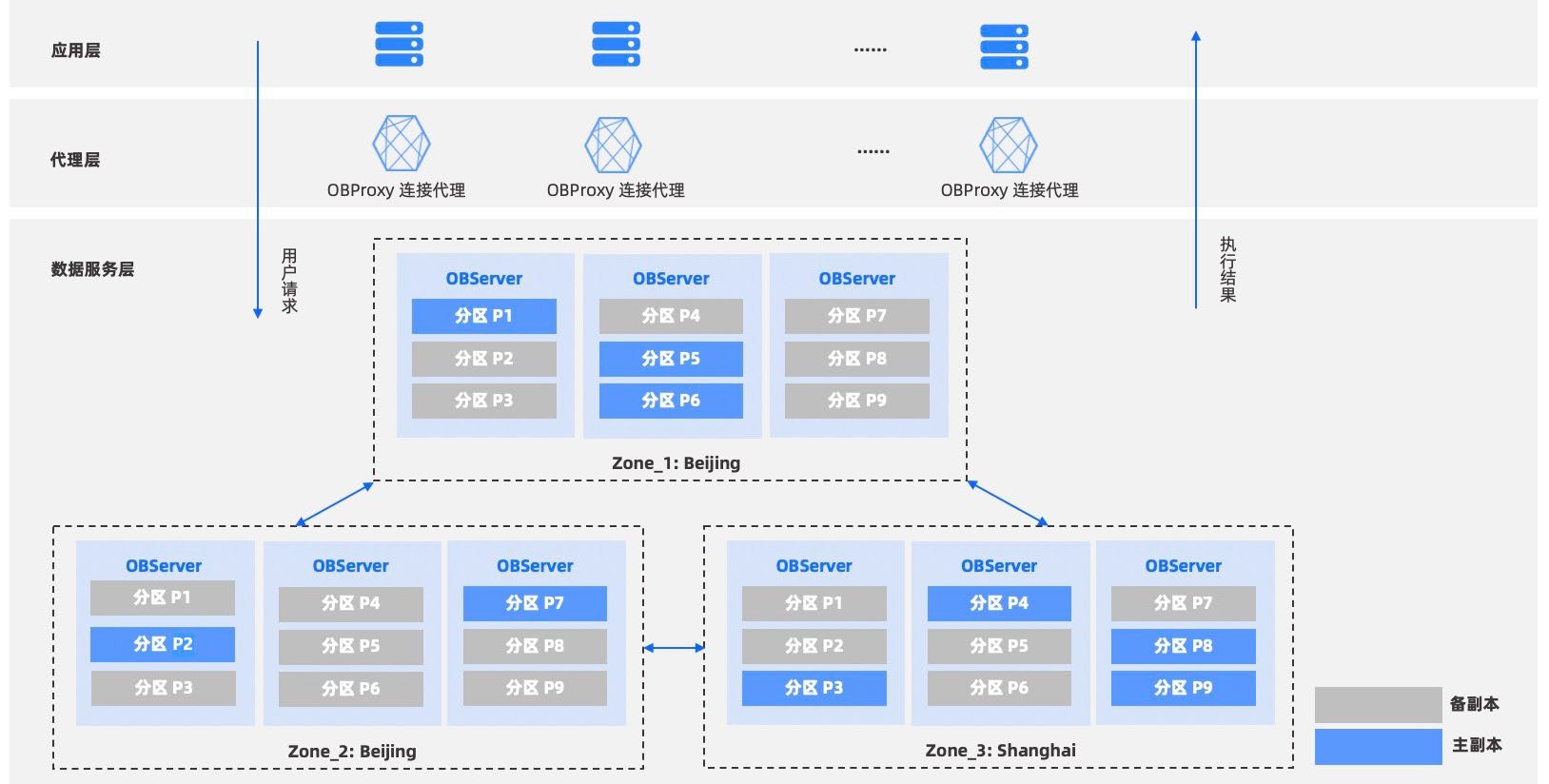
数据在不同的DN上有四种分布方式,可以在建表的时候指定:REPLICATION、HASH、RANGE、LIST。
GaussDB服务响应流程
相关概念
02
模式
01
表空间
在GaussDB中,表空间是一个目录, 可以存在多个,里面存储的是它所包含的数据库的各种物理文件。由于表空间是一个目录,仅是起到了物理隔离的作用, 其管理功能依赖于文件系统。
GaussDB的模式是对数据库做一个逻辑分割。所有的数据库对象都建立在模式下面。Gauss DB的模式和用户是弱绑定的, 所谓的弱绑定是指虽然创建用户的同时会自动创建一个同名模式,但用户也可以单独创建模式, 并且为用户指定其他的模式。
GaussDB使用用户和角色来控制对数
据库的访问。根据角色自身的设置不同,一个角色可以看做是一个数据库用户, 或者一组数据库用户。在Gauss DB中
角色和用户之间的区别只在于角色默认是没有LOGIN权限的。在GaussDB中一个用户唯一对应一个角色,不过可以使用角色叠加来更灵活地进行管理。
03
用户和角色




存储模型
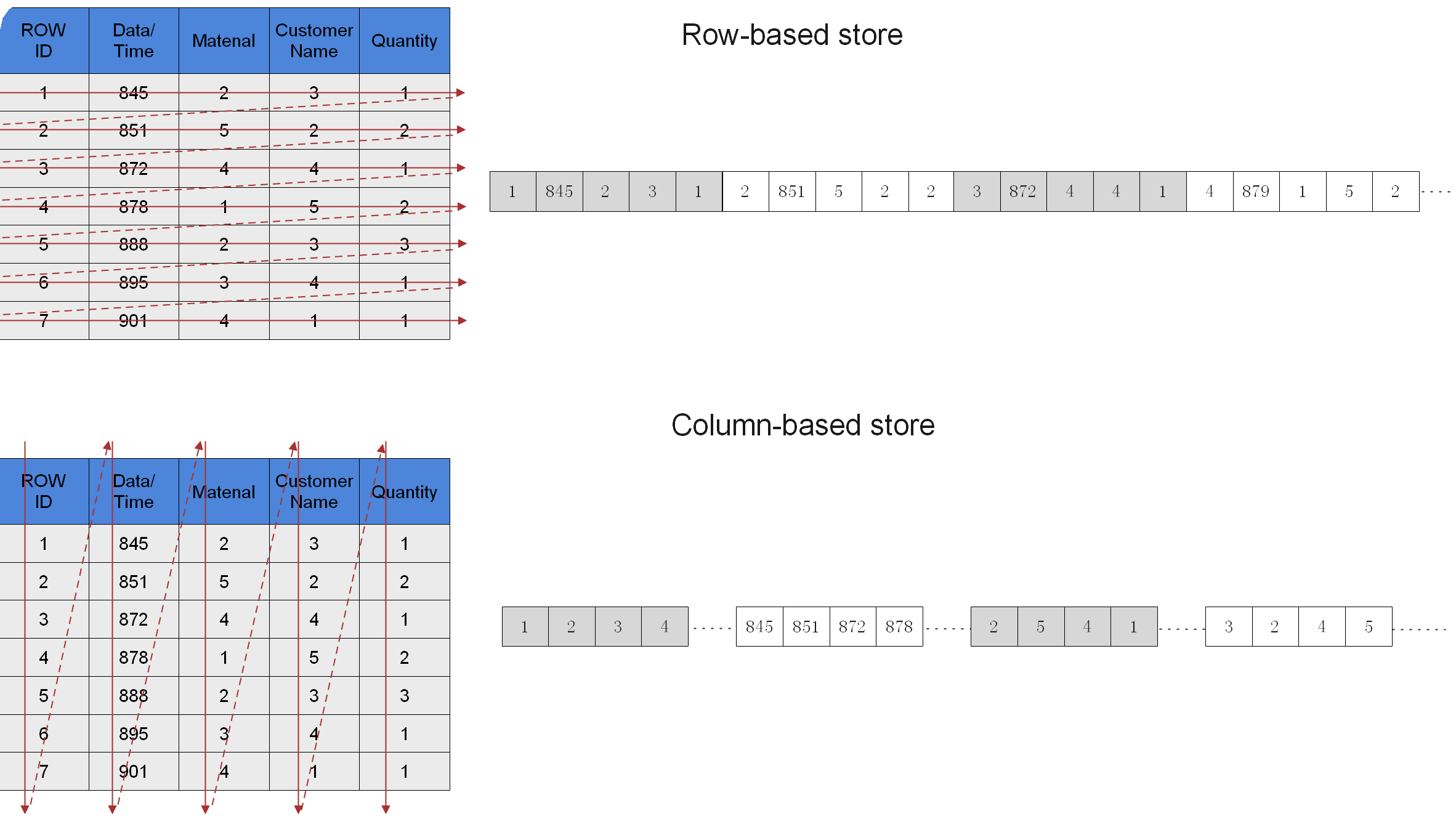
行存储和列
存储的差异
主持人笔记
2023-08-08 01:15:43
-—————————————————————-
存储模型优点
缺点行存
优点:数据被保存在一起。INSERT/UPDATE容易。缺点:选择(Selection)时即使只涉及某几列,所有数据也都会被读取。列存
优点:查询时只有涉及到的列会被读取。
投影(Projection)很高效。任何列都能作为索引。
缺点:选择完成时,被选择的列要重新组装。 INSERT/UPDATE比较麻烦。
一般情况下,如果表的字段比较多(大宽表),查询中涉及到的列不多的情况下,适合列存储。如果表的字段个数比较少,查询大部分字段,那么选择行存储比较好。行存表和列存表的选择
更新频繁程度
数据如果频繁更新,选择行存表。插入频繁程度
频繁的少量插入,选择行存表。一次插入大批量数据,选择列存表。表的列数
表的列数很多,选择列存表。查询的列数
如果每次查询时,只涉及了表的少数(<50%总列数)几个列,选择列存表。压缩率
列存表比行存表压缩率高。但高压缩率会消耗更多的CPU资源。
- 建立在一个表的子集上的索引,这种索引方式只包含满足条件表达式的元组。
- 创建部分索引
- 例:如果只需要查询ca_address_sk为5050的记录,可以创建部分索引来提升查询效率。
- gaussdb=# CREATE INDEX part_index ON
- 例:如果只需要查询ca_address_sk为5050的记录,可以创建部分索引来提升查询效率。
tpcds.customer_address_bak(ca_address_sk) WHERE
ca_address_sk = 5050;
部分索引
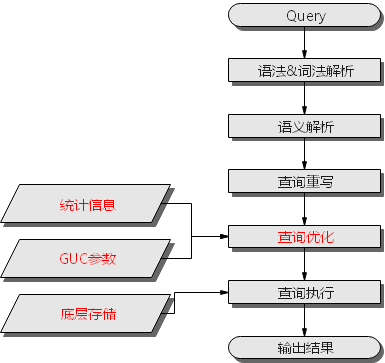
Query执行流程
根据“查询重写”的输出和数据库内部的统计信息规划SQL语句具体的执行方式,也就是执行计划。统计信息和GUC参数对
查询优化(执行计划)的影响
主持人笔记
2023-08-08 01:15:44
-—————————————————————-
调优手段之统计信息
GaussDB优化器是典型的基于代价的优化 (Cost-Based Optimization,简称CBO)。在这种优化器模型下,数据库根据表的元组数、字段宽度、NULL记录比率、distinct值、MCV值、HB值等表的特征值,以及一定的代价计算模型,计算出每一个执行步骤的不同执行方式的输出元组数和执行代价(cost),进而选出整体执行代价最小/首元组返回代价最小的执行方式进行执行。这些特征值就是统计信息。从上面描述可以看出统计信息是查询优化的核心输入,准确的统计信息将帮助规划器选择最合适的查询规划,一般来说通过analyze语法收集整个表或者表的若干个字段的统计信息,周期性地运行ANALYZE,或者在对表的大部分内容做了更改之后马上运行它是个好习惯。
调优手段之GUC参数
查询优化的主要目的是为查询语句选择高效的执行方式。
如下SQL语句:
select count(1)
from customer inner join store_sales on (ss_customer_sk = c_customer_sk);
在执行customer inner join store_sales的时候,GaussDB支持Nested Loop、Merge Join和Hash Join三
种不同的Join方式。优化器会根据表customer和表store_sales的统计信息估算结果集的大小以及每种join
方式的执行代价,然后对比选出执行代价最小的执行计划。
正如前面所说,执行代价计算都是基于一定的模型和统计信息进行估算,当因为某些原因代价估算不能
反映真实的cost的时候,就需要通过guc参数设置的方式让执行计划倾向更优规划。
存储引擎
Astore&Usto
re
Astore与Ustore的多版本实现最大的区别在于最新版本和历史版本是否分离存储。
Astore不进行分离存储,而Ustore当前也只是分离了数据,索引本身没有分开。
Ustore存储引擎,又名In-place Update存储引擎(原地更新),是GaussDB(for openGauss) 内核新增的一种存储模式。GaussDB(for openGauss) 内核此前的版本使用的行存储引擎是Append Update(追加更新)模式。追加更新对于业务中的增、删以及HOT(Heap Only Tuple) Update(即同一页面内更新)有很好的表现,但
对于跨数据页面的非HOT UPDATE场景,垃圾回收不够高效,因此,Ustore存储引
擎应运而生
连接数据库
//以下用例以gsjdbc4.jar为例。
//以下代码将获取数据库连接操作封装为一个接口,可通过给定用户名和密码来连接数据库。
public static Connection getConnect(String username, String passwd)
{
//驱动类。
String driver = “org.postgresql.Driver”;
//数据库连接描述符。
String sourceURL = “jdbc:postgresql://10.10.0.13:8000/postgres”;
Connection conn = null;
try
{
//加载驱动。 Class.forName(driver);
}
catch( Exception e )
{
e.printStackTrace(); return null;
}
try
{
//创建连接。
conn = DriverManager.getConnection(sourceURL, username, passwd); System.out.println(“Connection succeed!”);
}
catch(Exception e)
{
e.printStackTrace(); return null;
}
return conn;
}
03
Ocean Base
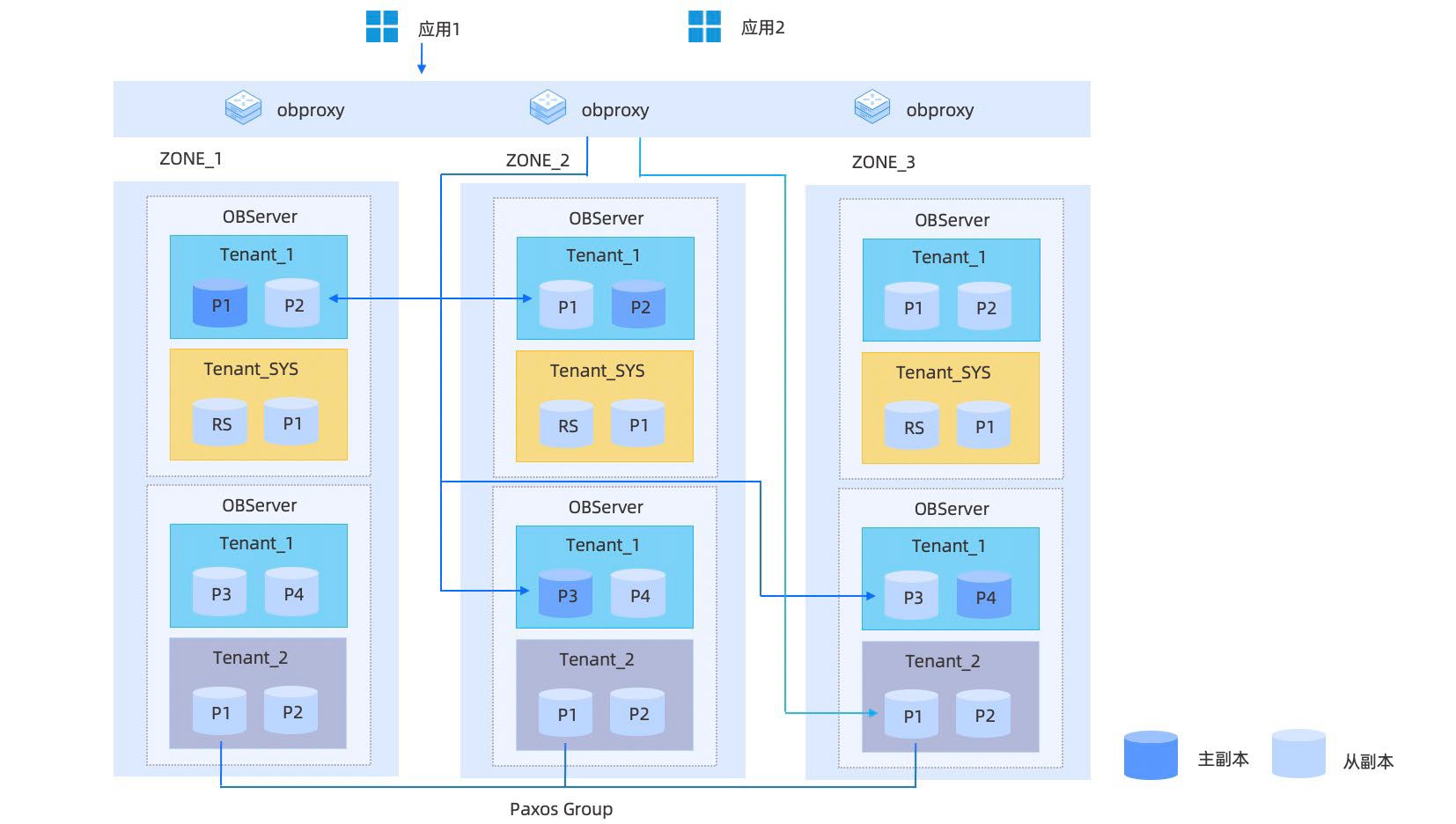
OceanBase 数据库整体架构
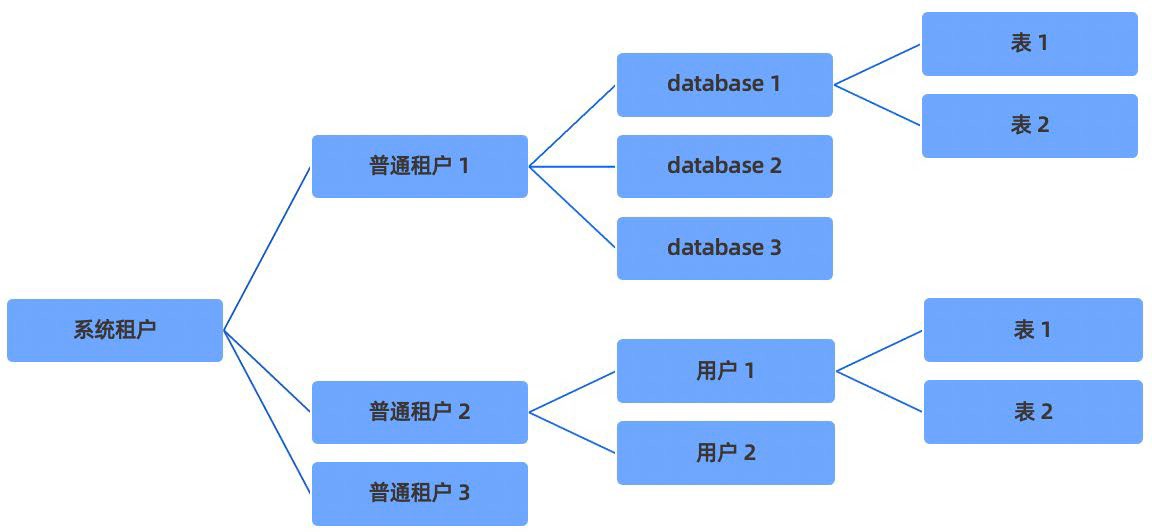
租户结构
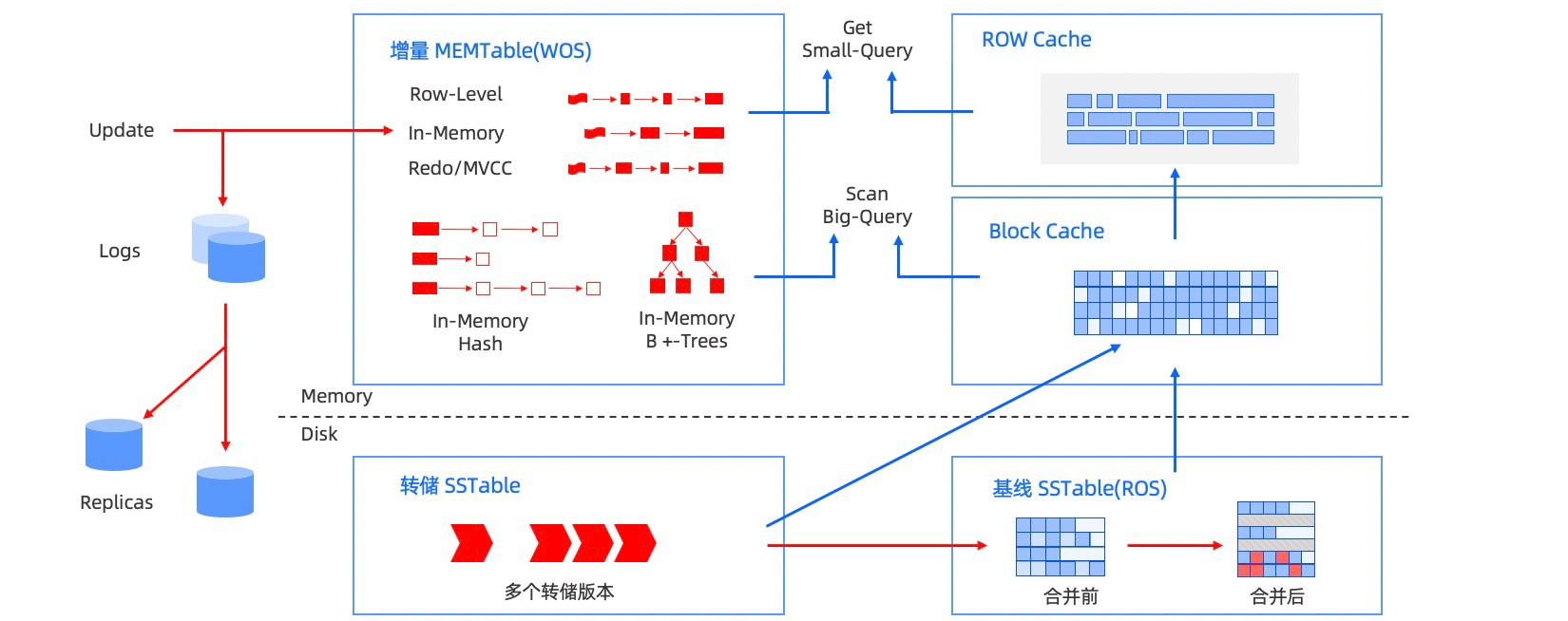
存储架构
主持人笔记
2023-08-08 01:15:45
-—————————————————————-
OceanBase 数据库的存储引擎基于 LSM Tree 架构,将数据分为静态基线数据(放在 SSTable 中)和动态增量数据(放在 MemTable 中)两部分,其中 SSTable 是只读的,一旦生成就不再被修改,存储于磁盘;MemTable 支持读写,存储于内存。数据库 DML 操作插入、更新、删除等首先写入 MemTable,等到 MemTable 达到一定大小时转储到磁盘成为 SSTable。在进行查询时,需要分别对 SSTable 和 MemTable 进行查询,并将查询结果进行归并,返回给 SQL 层归并后的查询结果。同时在内存实现了 Block Cache 和 Row cache,来避免对基线数据的随机读。当内存的增量数据达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据落盘。同时每天晚上的空闲时刻,系统也会自动每日合并。
OceanBase 数据库本质上是一个基线加增量的存储引擎,在保持 LSM-Tree 架构优点的同时也借鉴了部分传统关系数据库存储引擎的优点。
传统数据库把数据分成很多页面,OceanBase 数据库也借鉴了传统数据库的思想,把数据文件按照 2MB 为基本粒度切分为一个个宏块, 每个宏块内部继续拆分出多个变长的微块; 而在合并时数据会基于宏块的粒度进行重用, 没有更新的数据宏块不会被重新打开读取, 这样能够尽可能减少合并期间的写放大, 相较于传统的 LSM-Tree 架构数据库显著降低合并代价。另外,OceanBase 数据库通过轮转合并的机制把正常服务和合并时间错开,使得合并操作对正常用户请求完全没有干扰。
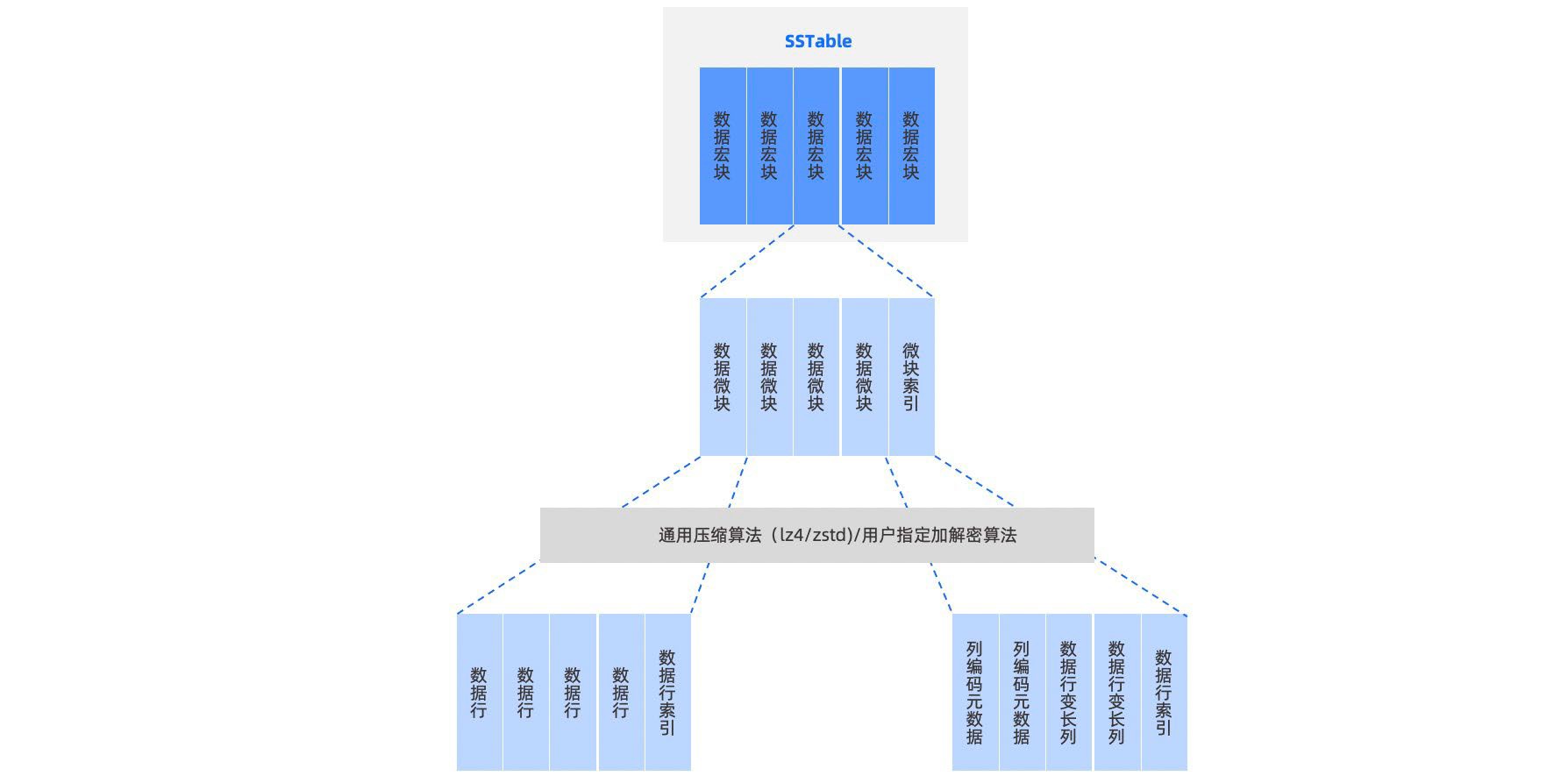
SSTable
主持人笔记
2023-08-08 01:15:45
-—————————————————————-
在 OceanBase 数据库中, 对于用户表每个分区管理数据的基本单元就是 SSTable,当 MEMTable 的大小达到某个阈值后,OceanBase 数据库会将 MEMTable 冻结,然后将其中的数据转存于磁盘上,转储后的结构就称之为 SSTable 或者是 Minor SSTable。当集群发生全局合并时,每个用户表分区所有的 Minor SSTable 会根据合并快照点一起参与做 Major Compaction,最后会生成 Major SSTable。每个 SSTable 的构造方式类似,都是由自身的元数据信息和一系列的数据宏块组成,每个数据宏块内部则可以继续划分为多个微块,根据用户表模式定义的不同,微块可以选择使用平铺模式或者编码格式进行数据行的组织。
OceanBase 数据库体系架构
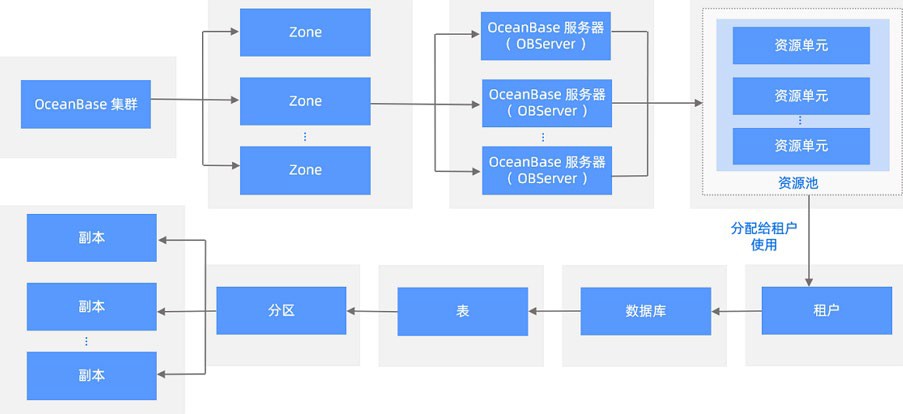
OceanBase 数据库基础概念之间的关系
数据均衡
OceanBase 数据库通过 RootService 管理租户内各个资源单元间的负载均衡。不同类型的副本需求的资源各
不相同,RootService 在执行分区管理操作时需要考虑的因素包括每个资源单元的 CPU、磁盘使用量、内存使用量、IOPS 使用情况。经过负载均衡,最终会使得所有机器的各类型资源占用都处于一种比较均衡的状
态,充分利用每台机器的所有资源。
- 副本均衡
RootService 会通过副本迁移的方式,调整租户和副本在各个 Unit 上的分布情况。
- Leader 均衡
在副本均衡的基础上,RootService 会根据租户 Primary Zone 等因素,均衡各机器分区 Leader 数目。通过
把分区 Leader 聚集到同一机器上,减少分布式事务执行的可能,减少业务请求的 RT;通过把分区 Leader
在多机上打散,最大限度利用机器资源,提高系统吞吐能力。
客户端连接OceanBase
命令行终端OBClient
$obclient -h10.0.0.0 -P2881 -usys@Oracle -p****** -A
租户连接账户格式:用户名@租户名#集群名
通过 ODC 连接 OceanBase 数据库
ODC分为windows客户端版本和Web版本
Web版本的需要账户密码登录使用,windows客户端不需要账户
功能与oracle的PLSQL Developer功能类似,包含sql美化、查看执行计划、数据导出、导入、等功能。
应用程序连接 OceanBase 数据库
获取 OceanBase Connector/J 驱动程序安装包
import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; public class HelloWorld {
public static void main(String[] args) { try {
String url = “jdbc:oceanbase://ipaddress:port/shemaname?pool=false”; String user = “username”;
String password = “password”; Class.forName(“com.oceanbase.jdbc.Driver”);
Connection connection = DriverManager.getConnection(url, user, password);
} catch (ClassNotFoundException e) { e.printStackTrace();
}
username 的格式为:String username = “用户名@租户#集群”
}
DDL 支持的数据库对象范围
OceanBase DDL 支持的数据库对象有:
- 表,包括约束、索引
- 视图
- 序列
- 同义词
- 自定义函数
- 存储过程
- 触发器
- 包和包体
数据导出、导入工具
OBDUMPER 是一款使用 Java 开发的客户端导出工具。可以使用该工具将 OceanBase 数据库中定义的对象结构和数据导出到文件中。
例:导出scms_sdp1库的ddl及数据 ,ddl脚本带drop语句
./obdumper -h 10.5.10.209 -P 2883 -u scms_sdp1 -p SCms_sdp@123 —sys-password PAssword01## -c hbnxpoc -t loandb -D SCMS_SDP1 —ddl —csv —all —drop-object —thread 100 -f
/obbackup/obdumper/scms_sdp
OBLOADER 是一款使用 Java 开发的客户端导入工具。该工具提供了非常灵活的命令行选项,可在多种复杂的场景下,将结构和数据导入到 OceanBase 数据库中。
例:将scms_sdp1备份的数据导入scms_sdp库中
./obloader -h 10.5.10.209 -P 2883 -u scms_sdp -p SCms_sdp@123 —sys-password PAssword01## -c
hbnxpoc -t loandb -D SCMS_SDP —ddl —csv —all —thread 100 -f /obbackup/obdumper/scms_sdp
04
Golden DB
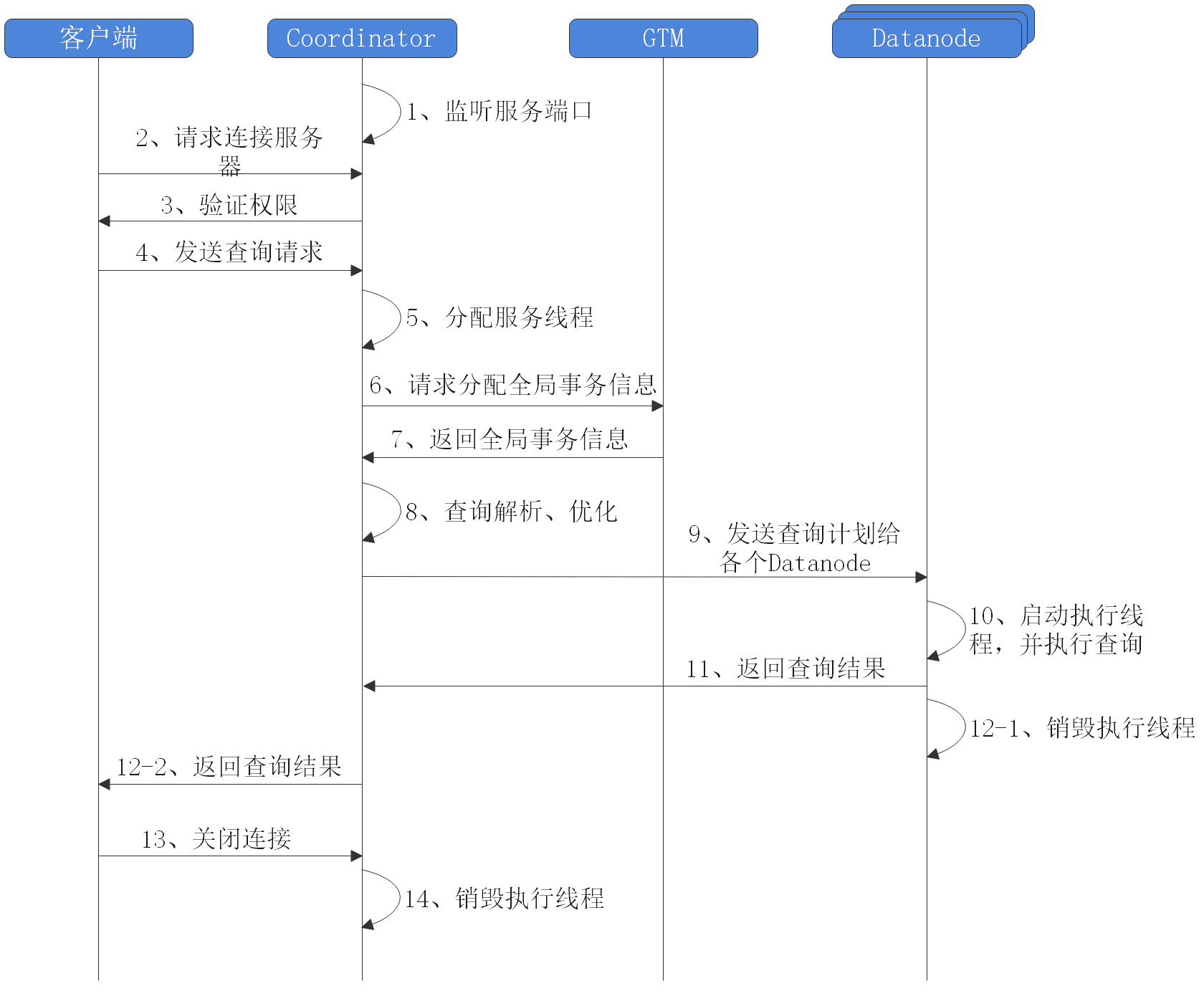
GoldenDB简介
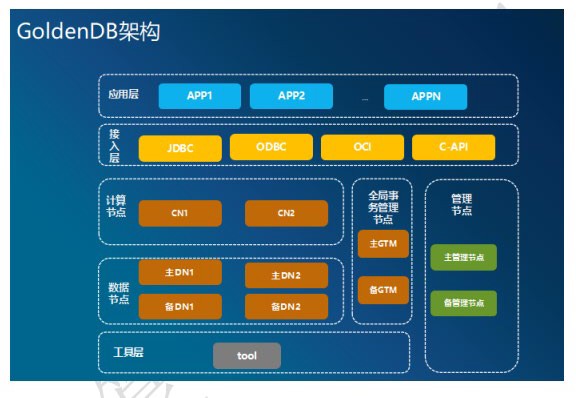
GoldenDB是自主研发的分布式数据库系统,整体由计算节点、数据节点、全局事
务管理器、管理节点四种核心模块组成,外围包含导入导出模块,以及相关的备 份、恢复等运维工具。整个系统采用高可靠性设计无单点故障,计算节点为无状 态多节点部署,数据集群内由多个安全分片组构成,每个安全分片组内数据节点 主备多机部署,全局事务管理器主备多机部署。支持多集群及动态扩容,每个集 群由多个安全分片组组成,每个安全分片组内部包含主备复制关系的数据库节点,可动态对集群内的安全分片组数量进行扩容以及动态增加集群的数量。通过全局 事务管理器支持多节点的分布式事务,保证数据一致性。兼容SQL92、SQL99、
SQL2003标准语法,完全兼容MySQL语法,兼容常用Oracle、DB2语法。
GoldenDB架构图
主持人笔记
2023-08-08 01:15:47
-—————————————————————-
GoldenDB是自主研发的分布式数据库系统,整体由计算节点、数据节点、全局事务管理器、管理节点四种核心模块组成,各个节点无需共享任何资源,都是独立自治的通用计算机节点,之间通过高速互联的网络通讯,从而完成对应用数据请求的快速处理和响应。数据节点
数据节点集群是应用数据的最终存储模块。所有的数据节点组成一个或多个数据库集群,用户操作的事务不可以跨越多个数据库集群,只能在一个数据库集群内进行。数据库集群由一个或多个安全组组成,集群中每个表中的数据按照某种策略进行横向分片后存放到对应的安全组中,分片策略包括复制策略、哈希策略、范围策略、列表策略、多级分片。安全组是由一个或多个数据节点构成的数据库节点组,组内的数据库节点拥有相同的数据。当安全组中存在多个数据节点时,其中一个数据节点为主用节点,其他数据节点都为备用节点,数据在主备节点之间实时复制。主用节点具备读写能力,备用节点可以提供读能力。安全组内的数据节点数量越多,可靠性就越高,读能力也得以进一步扩展。计算节点
计算节点集群层是分布式数据库的核心层,由无状态的计算节点组成。计算节点从驱动层或者管理节点接收用户的操作(一般以结构化查询语言进行描述,Structured Query Language),进行逻辑优化和物理优化,生成满足分布式事务一致性的分布式查询计划。计算机节点在执行分布式查询计划时,通过持续地访问数据节点,从而完成用户的最终操作请求。用户可以根据应用对可靠性、可用性、性能等因素的不同要求,对计算节点进行合理的规划和划分。全局事务节点
全局事务管理器在分布式数据库中维护全局事务的全生命周期,提供申请、释放、查询全局事务的能力,采用双活方式部署。管理节点
管理节点在分布式数据库中负责集群管理流程,不涉及业务的访问流程,无负载压力,一般采用主备方式部署。管理节点按照功能分工,可分为如下几个子模块:
● 统一运维管理Insight
Insight是GoldenDB分布式数据库产品的统一操作维护入口,用户可以在Insight上进行用户和权限管理、元数据管理、计算节点管理、数据节点管理、DDL执行、节点扩容、备份恢复、系统安装、统计及告警管理等。
● 元数据管理器MetaDataServer
元数据指数据的元信息,如库、表、视图、触发器、存储过程、函数等数据模型的定义,元数据管理器存放系统的全量元数据,是整个分布式数据库集群的元数据中心。为了提高启动和运行效率,除了元数据管理器存有元数据定义外,计算节点和数据节点也会存放元数据定义,但计算机节点和数据节点只存放本节点所涉应用的元数据定义,即当计算节点中的元数据和管理节点的元数据不一致时,会同步管理节点的元数据到本地。此外,元数据管理器还保存了整个集群的拓扑信息,因此是更广义的元数据管理。
● 计算节点管理ProxyManager
负责管理计算节点集群。管理工作一般分为两类。一类为组建管理,包括计算节点的创建、启用、禁用和删除,另一类为应用管理,包括定义计算节点和应用的对应关系、计算节点异常后的数据恢复调度。
● 数据节点管理ClusterManager
数据节点集群管理也分为两类。一类为组建管理,包括数据节点、安全组、数据节点集群的创建、变更和删除;另一类为任务管理,包括数据节点异常、恢复后的调度管理、数据节点备份恢复的调度、数据重分布等功能的任务调度管理。
与Oracle兼容性
GoldenDB分布式数据库针对不同格式的数据定义了不同的数据类型,目前支持8种数据类型。
GoldenDB分布式数据库支持Oracle中常用的SQL语法,其支持的语法类别全面覆盖数据库语法类别,包括 DDL、DML、DQL等等。
Oracle数据库中共有内置函数257个,GoldenDB数据库目前支持89个。 GoldenDB数据库兼容Oracle数据库的PL(Procedural Language)功能
GoldenDB兼容大部分Oracle数据库的视图,兼容字典视图94个,兼容v$性能视图12个。
GoldenDB数据库的SQL引擎兼容大部分Oracle数据库的特性
兼容Oracle的SQL数据类型
GoldenDB数据类型
说明
FLOAT(5)
4字节单精度浮点数
NUMBER(n,s)
数值型,n为数值总长度,范围1-65,s为小数点后长度,范围0-30,s必须不大于n
DATE
日期,范围:1000-01-01 – 9999-12-31
TIMESTAMP
UTC日期和时间,范围:1970-01-01 00:00:01.000000 – 2038-01-19
03:14:07.999999
CHAR(10)
定长字符型,最多255个字符
BLOB
最大长度为65,535(216–1)字节的BLOB列
CLOB
最大长度为65,535(216–1)字节的BLOB列
VARCHAR2
支持VARCHAR2(num) 、VARCHAR2(num BYTE) 、VARCHAR2(num CHAR)
三种用法,前两种用法等价;存储过程参数类型为VARCHAR2且未指定长度时,默认长度为4000字节;
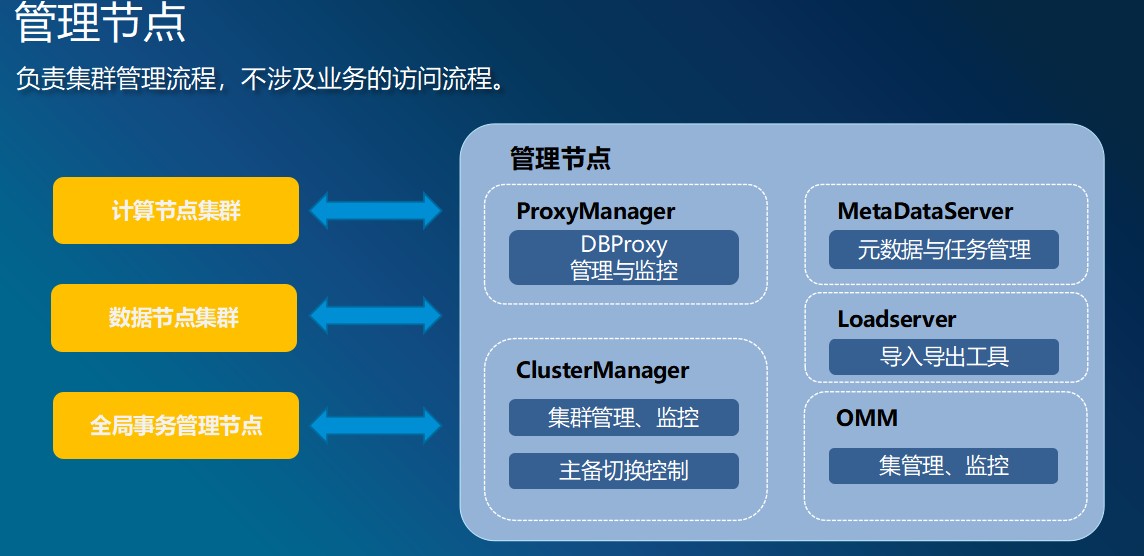
管理节点
主持人笔记
2023-08-08 01:15:47
-—————————————————————-
管理节点:是对系统计算节点集群、数据集群管理的节点,它承载了分布式数据库系统的所有的运维操作,包括集群高可用高可靠的管理、系统的备份恢复、系统元数据管理、数据迁移等操作。
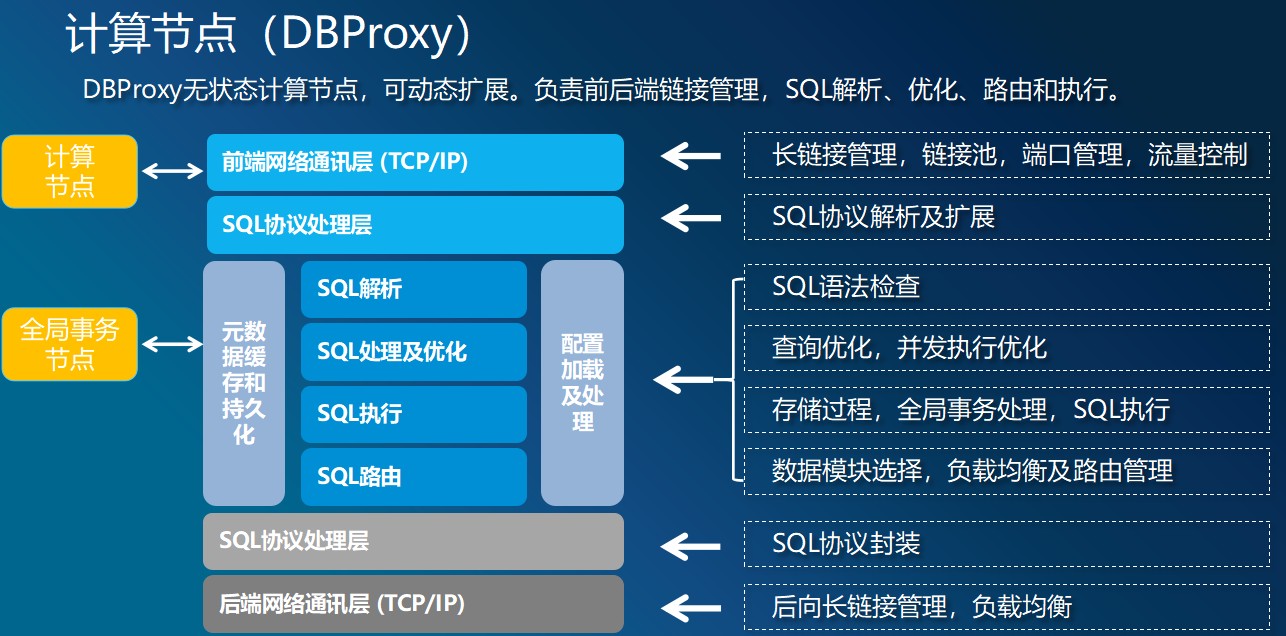
计算节点
主持人笔记
2023-08-08 01:15:47
-—————————————————————-
计算节点(CN:Computer Node)集群,这个集群内的节点我们称为CN节点。它的主要作用就是接受应用发送过来的业务语句,对业务语句做语法解析,根据数据的分布信息做分布式的优化,包括语句的改写,并行分发等等,最终生成分布式的执行计划,按照该执行计划将语句并行的下发到下一层的数据节点集群中。同时它还有一个重要的功能就是进行分布式事务的并发控制。
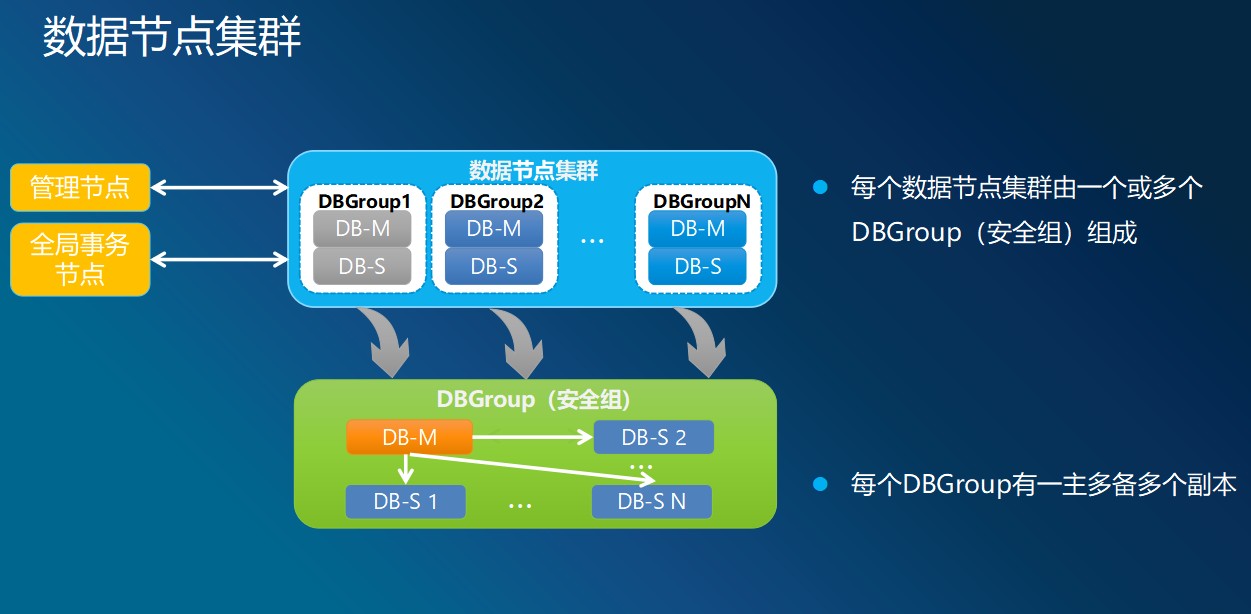
数据节点
主持人笔记
2023-08-08 01:15:47
-—————————————————————-
数据节点(DN:DataNode):是用于存储业务数据,及执行分布式子事务的节点。通常一个集群包含多个数据节点,每个数据节点都是独立自治的数据库系统,一个业务的数据只会落到一个数据集群中。业务的数据会被水平的切分后分布在若干个数据节点上,为了保证数据的可用性,我们会为每个数据分片部署多个数据备份节点,假如一个业务的数据分成了2份,如果1号分片坏了,1号分片的备份系统就会替代原分片。因此,数据分片节点和它的备份数据节点构成一个安全组。也就是虚线框住的数据节点。
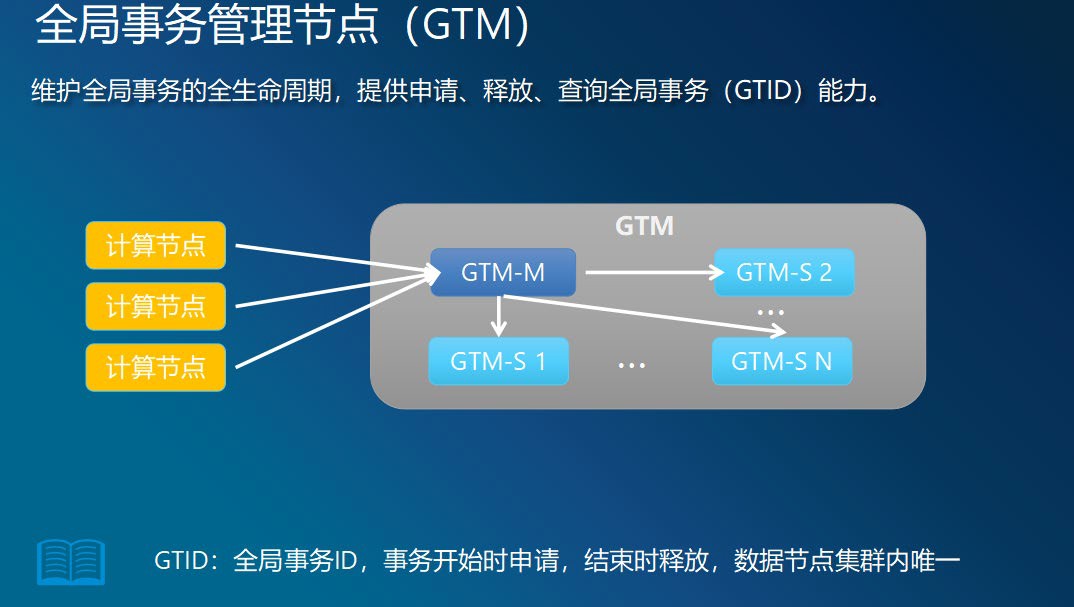
全局事务管理器GTM
主持人笔记
2023-08-08 01:15:48
-—————————————————————-
全局事务管理节点:(GTM:Global Transaction Manager),它是协调CN一起进行分布式事务的并发控制的,管理分布式事务的生命周期,负责维护一张当前所有正在执行的分布式事务列表。
GoldenDB 连接数据库
连接数据库的客户端工具包括MySQL客户端、应用程序接口(如JDBC)。
- MySQL客户端是开源的客户端工具。使用MySQL客户端连接数据库,可以交互式地输入、编辑、执行SQL语句。
- 可以使用标准的数据库应用程序接口(如JDBC),开发基于GoldenDB的应用程序。
创建表
依据分发策略,分布式数据库GoldenDB将数据存储分布在不同数据节点上。依据相应字段值可确定数据具体落在哪个分片的字段称为分片键。
目前支持四种分发策略:
- HASH分发。
- DUPLICATE分发
- RANGE分发
- LIST分发注意事项
建表时,需注意以下问题:
- 表名长度不可超过64字节。
- 字段名长度不可超过64字节。
- 表应指定主键。
TDSQL MySQL版
https://cloud.tencent.com/document/product/557
OceanBase 数据库
https://[www.oceanbase.com/docs/oceanbase-database](http://www.oceanbase.com/docs/oceanbase-database)
GaussDB
https://[www.huaweicloud.com/product/gaussdb.html](http://www.huaweicloud.com/product/gaussdb.html)
GoldenDB简介 https://[www.goldendb.com/#/docsIndex/docs/GoldenDB\_Introduction](http://www.goldendb.com/%23/docsIndex/docs/GoldenDB_Introduction) [TOC]


{kind=link}
{kind=link}